Comment installer et configurer kafka ?
Configuration de Kafka
- Télécharger la dernière version stable de Kafka à partir d’ici.
- Dézipper ce fichier.
- Aller dans le répertoire config.
- Changer le journal.
- Vérifier le zookeeper.
- Aller dans le répertoire d’accueil de Kafka et exécuter la commande ./bin/ kafka -server-start.sh config/server.
- Arrêter le courtier Kafka par la commande . /bin/ kafka -server-stop.sh .
De même, comment télécharger et installer Kafka ?
Télécharger et installer Kafka
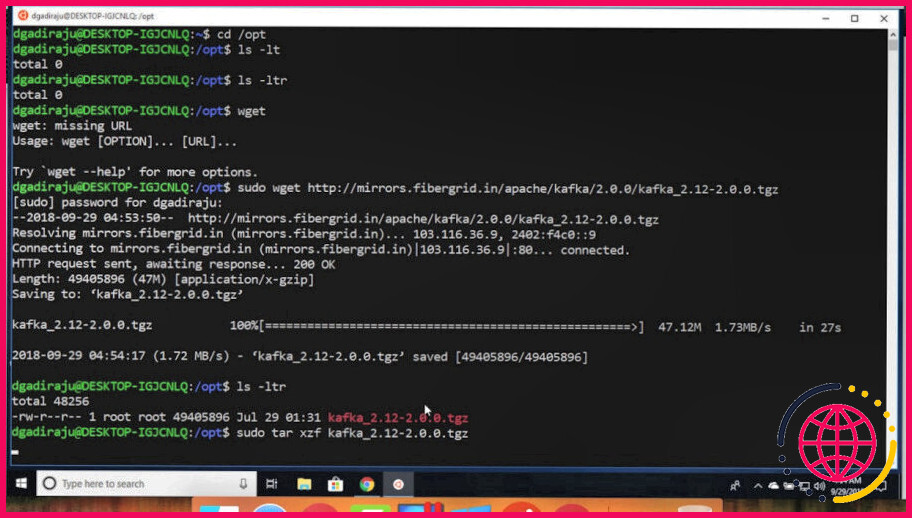
- Naviguer dans le répertoire de configuration de Kafka situé sous [kafka_install_dir]/config .
- Modifiez le fichier server. properties dans un éditeur de texte.
- Recherchez l’entrée » log. dirs=/tmp/kafka-logs » et changez-la en » log. dirs=C:/temp/kafka-logs « . Assurez-vous d’utiliser des barres obliques dans le nom du chemin !
Deuxièmement, comment puis-je définir les variables d’environnement dans Kafka ? Configurer Apache Kafka.
- Définir les variables d’environnement pour Kafka.
- Ouvrir les propriétés du système.
- Cliquer sur « Variables d’environnement » et ajouter une nouvelle « Variable système » comme suit.
- Cliquer sur « Nouveau » et créer la variable « KAFKA_HOME ».
- Ajouter « %KAFKA_HOME%in » dans la variable « Path ».
Les gens demandent également, comment puis-je exécuter Kafka localement ?
Démarrage rapide
- Etape 1 : Télécharger le code. Télécharger la 2.4.
- Etape 2 : Démarrer le serveur.
- Etape 3 : Créer un topic.
- Etape 4 : Envoyer quelques messages.
- Etape 5 : Démarrer un consumer.
- Etape 6 : Configurer un cluster multi-broker.
- Etape 7 : Utiliser Kafka Connect pour importer/exporter des données.
- Étape 8 : Utiliser Kafka Streams pour traiter les données.
Comment installer ZooKeeper et Kafka sur Windows ?
Voici les étapes pour installer Kafka sur Windows : Avant de commencer à installer Kafka , vous devez installer Zookeeper . Une fois qu’il est téléchargé, extraire les fichiers et copier le dossier kafka dans le lecteur C. Maintenant, dans le dossier kafka , à l’intérieur du dossier config, vous trouverez un fichier nommé server.
Comment fonctionne Kafka ?
Comment est-ce qu’il fonctionne ? Les applications (producteurs) envoient des messages (enregistrements) à un nœud Kafka (broker) et lesdits messages sont traités par d’autres applications appelées consommateurs. Lesdits messages sont stockés dans un sujet et les consommateurs s’abonnent au sujet pour recevoir de nouveaux messages.
À quoi sert Kafka ?
Kafka est une plateforme de streaming distribuée qui est utilisée pour publier et s’abonner à des flux d’enregistrements. Kafka est utilisé pour le stockage tolérant aux pannes. Kafka réplique les partitions de journaux de sujets sur plusieurs serveurs. Kafka est conçu pour permettre à vos apps de traiter les enregistrements à mesure qu’ils se produisent.
Kafka est-il gratuit ?
Kafka lui-même est complètement gratuit et open source. Confluent est la société à but lucratif des créateurs de Kafka . La plateforme Confluent est Kafka plus divers extras tels que le registre de schémas et les connecteurs de base de données.
Quelle version de Kafka ai-je ?
jar , où 2.10 est la version de Scala et 0.8. 2-beta est la version de Kafka. de votre dossier kafka (et il fera de même pour vous). Il vous retournera quelque chose comme kafka_2 .
Est-ce que Kafka est open source ?
Apache Kafka est une open – source plateforme logicielle de traitement de flux développée par LinkedIn et donnée à l’Apache Software Foundation, écrite en Scala et Java. Le projet vise à fournir une plateforme unifiée, à haut débit et à faible latence pour traiter les flux de données en temps réel.
Qu’est-ce que ZooKeeper dans Kafka ?
ZooKeeper est un logiciel construit par Apache qui est utilisé pour maintenir les données de configuration et de nommage ainsi que pour fournir une synchronisation robuste et flexible dans les systèmes distribués. Il agit comme un service centralisé et aide à garder la trace de l’état des nœuds du cluster Kafka , des sujets Kafka et des partitions.
Qu’est-ce que le client Kafka ?
La première partie de Apache Kafka pour les débutants explique ce qu’est Kafka – un système de messagerie durable basé sur la publication et l’abonnement qui échange des données entre les processus, les applications et les serveurs. Il vous donnera une brève compréhension de la messagerie et des journaux distribués, et les concepts importants seront définis.
Comment puis-je me connecter au cluster Kafka ?
Pour connecter au cluster Kafka à partir du même réseau où il fonctionne, utilisez un Kafka client et accédez au port 9092. Vous pouvez trouver un exemple utilisant le Kafka intégré.
client sur la page Kafka producteur et consommateur.
Kafka peut-il fonctionner sans zookeeper ?
Kafka 0.9 peut fonctionner sans Zookeeper après que tous les courtiers Zookeeper soient arrêtés. Après avoir tué les trois nœuds Zookeeper , le cluster Kafka continue de fonctionner.
Comment puis-je savoir si Kafka est installé ?
Re : Comment vérifier la version de Kafka
Si vous utilisez HDP via Ambari, vous pouvez utiliser la fonctionnalité Stacks and Versions pour voir tous les composants installés et les versions de la pile . Via la ligne de commande, vous pouvez naviguer vers /usr/hdp/current/ kafka -broker/libs et voir les fichiers jar avec les versions.
Comment me connecter à Kafka ?
Approche
- Installer une instance de serveur Kafka localement à des fins d’évaluation.
- Exécuter le serveur Kafka et créer un nouveau sujet.
- Configurer l’Atom local avec les bibliothèques client Kafka.
- Créer un processus d’intégration AtomSphere pour publier des messages sur le sujet Kafka via un script personnalisé Groovy.
Combien de temps Kafka stocke-t-il les données ?
Par exemple, si la politique de rétention est définie sur deux jours, alors pendant les deux jours suivant la publication d’un enregistrement, il est disponible pour la consommation, après quoi il sera écarté pour libérer de l’espace. un message restera au topic pendant 3 minutes.
Comment puis-je exécuter un serveur Kafka ?
Configuration de Kafka
- Télécharger la dernière version stable de Kafka à partir d’ici.
- Dézipper ce fichier.
- Aller dans le répertoire de configuration.
- Changer le log.
- Vérifier le zookeeper.
- Allez dans le répertoire home de Kafka et exécutez la commande ./bin/kafka-server-start.sh config/server.
- Arrêtez le courtier Kafka par la commande ./bin/kafka-server-stop.sh .
Comment tester un consommateur Kafka ?
1 Réponse
- Vous devez démarrer zookeeper et kafka de manière programmatique pour les tests d’intégration.
- Émettre quelques événements à streamer en utilisant KafkaProducer.
- Puis consommer avec votre consommateur pour tester et vérifier son fonctionnement.
Où Kafka stocke-t-il les données ?
Et dans ce cas, ce sont les messages poussés dans Kafka qui sont stockés sur le disque. En référence au stockage dans Kafka , vous entendrez toujours deux termes, Partition et Topic. Les partitions sont les unités de stockage dans Kafka pour les messages. Et le Topic peut être considéré comme étant un conteneur dans lequel se trouvent ces partitions.
Quel est le port utilisé par Kafka ?
Kafka écoute sur TCP port 9092.
Combien de nœuds zookeeper possède Kafka ?
Vous avez besoin d’un minimum de 3 nœuds zookeeper et de 2 Kafka brokers pour avoir un cluster à tolérance de panne correct. Le cluster à tolérance de pannes minimum recommandé serait de 3 Kafka brokers et 3 nœuds zookeeper avec un facteur de réplication = 3 sur tous les sujets.
Si vous utilisez HDP via Ambari, vous pouvez utiliser la fonctionnalité Stacks and Versions pour voir tous les composants installés et les versions de la pile. Via la ligne de commande, vous pouvez naviguer vers /usr/hdp/current/kafka-broker/libs et voir les fichiers jar avec les versions." } }, {"@type": "Question","name": " Comment me connecter à Kafka ? ","acceptedAnswer": {"@type": "Answer","text": "Approche
Installer une instance de serveur Kafka localement à des fins d'évaluation. Exécuter le serveur Kafka et créer un nouveau sujet. Configurer l'Atom local avec les bibliothèques client Kafka. Créer un processus d'intégration AtomSphere pour publier des messages sur le sujet Kafka via un script personnalisé Groovy. " } }, {"@type": "Question","name": " Combien de temps Kafka stocke-t-il les données ? ","acceptedAnswer": {"@type": "Answer","text": " Par exemple, si la politique de rétention est définie sur deux jours, alors pendant les deux jours suivant la publication d'un enregistrement, il est disponible pour la consommation, après quoi il sera écarté pour libérer de l'espace. un message restera au topic pendant 3 minutes." } }, {"@type": "Question","name": " Comment puis-je exécuter un serveur Kafka ? ","acceptedAnswer": {"@type": "Answer","text": "Configuration de Kafka
Télécharger la dernière version stable de Kafka à partir d'ici. Dézipper ce fichier. Aller dans le répertoire de configuration. Changer le log. Vérifier le zookeeper. Allez dans le répertoire home de Kafka et exécutez la commande ./bin/kafka-server-start.sh config/server. Arrêtez le courtier Kafka par la commande ./bin/kafka-server-stop.sh . " } }, {"@type": "Question","name": " Comment tester un consommateur Kafka ? ","acceptedAnswer": {"@type": "Answer","text": "1 Réponse
Vous devez démarrer zookeeper et kafka de manière programmatique pour les tests d'intégration. Émettre quelques événements à streamer en utilisant KafkaProducer. Puis consommer avec votre consommateur pour tester et vérifier son fonctionnement. " } }, {"@type": "Question","name": " Où Kafka stocke-t-il les données ? ","acceptedAnswer": {"@type": "Answer","text": " Et dans ce cas, ce sont les messages poussés dans Kafka qui sont stockés sur le disque. En référence au stockage dans Kafka, vous entendrez toujours deux termes, Partition et Topic. Les partitions sont les unités de stockage dans Kafka pour les messages. Et le Topic peut être considéré comme étant un conteneur dans lequel se trouvent ces partitions." } }, {"@type": "Question","name": " Quel est le port utilisé par Kafka ? ","acceptedAnswer": {"@type": "Answer","text": " Kafka écoute sur TCP port 9092." } }] }