La forêt aléatoire sera-t-elle surajustée ?
La forêt aléatoire est un algorithme d’apprentissage automatique populaire utilisé à la fois pour les tâches de classification et de régression. Il s’agit d’un type d’apprentissage d’ensemble, ce qui signifie qu’il utilise une combinaison de plusieurs modèles pour créer un modèle plus précis que n’importe lequel des modèles individuels pourrait créer par lui-même.
L’un des avantages de Random Forest est qu’il est moins susceptible de se suradapter que d’autres algorithmes d’apprentissage automatique, tels que les arbres de décision. En effet, chaque arbre de l’ensemble Random Forest est formé sur un sous-ensemble aléatoire de données, et les prédictions finales sont faites en faisant la moyenne des prédictions de tous les arbres. Cela signifie que si un arbre dépasse, il sera compensé par les autres arbres de l’ensemble.
Cependant, il existe encore des cas où Random Forest peut sur-adapter. Cela peut se produire si les données sont très bruitées ou s’il y a trop peu d’exemples d’apprentissage. Dans ces cas, il est possible que tous les arbres de la forêt aléatoire finissent par se suradapter.
Si vous craignez que votre modèle de forêt aléatoire ne soit surajusté, vous pouvez utiliser la validation croisée pour l’évaluer. Cela vous aidera à déterminer si votre modèle se généralise bien ou non aux nouvelles données. Vous pouvez également consulter les importances des fonctionnalités pour voir si le modèle accorde trop de poids à certaines fonctionnalités.
Dans l’ensemble, Random Forest est un puissant algorithme d’apprentissage automatique qui résiste au surajustement. Cependant, dans certains cas, cela peut encore se produire. Si vous craignez un surajustement, vous pouvez utiliser la validation croisée ou examiner l’importance des fonctionnalités pour vous aider à le détecter.
Overfitting. Les forêts aléatoires ne s’adaptent pas trop. La performance de test des forêts aléatoires ne diminue pas (à cause du surajustement) lorsque le nombre d’arbres augmente. Par conséquent, après un certain nombre d’arbres, la performance a tendance à rester dans une certaine valeur.
Quelles sont les causes de l’overfit des forêts aléatoires ?
Nous pouvons clairement voir que le modèle Random Forest est overfitting lorsque la valeur du paramètre est très faible (lorsque la valeur du paramètre. < 100), mais les performances du modèle remontent rapidement et rectifient le problème de surajustement (100 < valeur du paramètre < 400).
Comment corriger l’overfitting de la forêt aléatoire ?
1 Réponse
- n_estimateurs : Plus il y a d’arbres, moins l’algorithme est susceptible de se surajuster.
- max_features : Vous devriez essayer de réduire ce nombre.
- max_depth : Ce paramètre réduira la complexité des modèles appris, diminuant le risque de surajustement.
- min_samples_leaf : Essayez de définir ces valeurs supérieures à un.
L’arbre de décision est-il toujours surajusté ?
Dans les arbres de décision, l’élagage est un processus qui est appliqué pour contrôler ou limiter la profondeur (taille) des arbres. Par défaut, les hyperparamètres du modèle d’arbre de décision ont été créés pour faire croître l’arbre dans toute sa profondeur. Ces arbres sont appelés arbres à croissance complète qui sont toujours surajustés.
La forêt aléatoire est-elle meilleure que l’arbre de décision ?
Mais la forêt aléatoire choisit les caractéristiques de façon aléatoire pendant le processus de formation. Par conséquent, elle ne dépend pas fortement d’un ensemble spécifique de caractéristiques. Par conséquent, la forêt aléatoire peut généraliser sur les données d’une meilleure manière. Cette sélection aléatoire des caractéristiques rend la forêt aléatoire beaucoup plus précise qu’un arbre de décision.
La forêt aléatoire est-elle supervisée ou non supervisée ?
Une forêt aléatoire est un algorithme d’apprentissage automatique supervisé qui est construit à partir d’algorithmes d’arbres de décision. Cet algorithme est appliqué dans diverses industries telles que la banque et le commerce électronique pour prédire le comportement et les résultats.
La forêt aléatoire a-t-elle besoin d’une régularisation ?
3 Réponses . La forêt aléatoire a une régularisation, c’est juste pas sous la forme d’une pénalité à la fonction de coût. La forêt aléatoire n’a pas de fonction de coût globale dans le même sens que la régression linéaire ; elle se contente de maximiser avidement le gain d’information à chaque fractionnement.
Comment savoir si vous faites de l’overfitting ?
L’overfitting peut être identifié en vérifiant les métriques de validation telles que la précision et la perte. Les métriques de validation augmentent généralement jusqu’à un point où elles stagnent ou commencent à décliner lorsque le modèle est affecté par le surajustement.
Comment élaguer les arbres dans une forêt aléatoire ?
Contrairement à un arbre, aucun élagage n’a lieu dans une forêt aléatoire, c’est-à-dire que chaque arbre est cultivé pleinement. Dans les arbres de décision, l’élagage est une méthode pour éviter le surajustement. L’élagage consiste à sélectionner un sous-arbre qui conduit au taux d’erreur de test le plus faible.
XGBoost prend-il plus de temps que la forêt aléatoire ?
Chaque arbre ne peut être construit qu’après le précédent et chaque arbre est construit en utilisant tous les cœurs. Cela fait de XGBoost un algorithme très rapide. Le principal inconvénient des forêts aléatoires est leur complexité. Elles sont beaucoup plus difficiles et longues à construire que les arbres de décision.
Quelle est la différence entre l’arbre de décision et la forêt aléatoire ?
Un arbre de décision combine quelques décisions, alors qu’une forêt aléatoire combine plusieurs arbres de décision. Ainsi, c’est un processus long, mais lent. Alors qu’un arbre de décision est rapide et fonctionne facilement sur de grands ensembles de données, en particulier le linéaire. Le modèle de forêt aléatoire nécessite un entraînement rigoureux.
Comment améliorer la précision de la forêt aléatoire ?
Si vous souhaitez accélérer votre forêt aléatoire, diminuez le nombre d’estimateurs. Si vous souhaitez augmenter la précision de votre modèle, augmentez le nombre d’arbres. Spécifiez le nombre maximum de caractéristiques à inclure à chaque fractionnement de nœud. Cela dépend très fortement de votre ensemble de données.
Les forêts aléatoires utilisent-elles un élagage automatique ?
Random Forest est une technique d’apprentissage automatique supervisée d’ensemble. Il existe un champ de recherche pour analyser le comportement de la forêt aléatoire, générer des arbres de décision de base précis et diversifiés, un algorithme d’élagage vraiment dynamique pour le classificateur Random Forest et générer un sous-ensemble optimal de la forêt aléatoire.
Pourquoi n’y a-t-il pas d’élagage explicite des arbres dans la forêt aléatoire ?
Grosso modo, une partie du surajustement potentiel qui pourrait se produire dans un seul arbre (ce qui est une raison pour laquelle vous faites l’élagage en général) est atténuée par deux choses dans une Random Forest : Le fait que les échantillons utilisés pour former les arbres individuels sont « bootstrapped ».
Comment sélectionner MTRY dans une forêt aléatoire ?
Il y a deux façons de trouver le mtry optimal : Appliquer une procédure similaire telle que la forêt aléatoire est exécutée 10 fois. Le nombre optimal de prédicteurs sélectionnés pour le split est sélectionné pour lequel le taux d’erreur out of bag se stabilise et atteint le minimum.
A quoi ressemble l’overfitting ?
Dans le graphique ci-dessous, nous pouvons voir des signes clairs de surajustement : La perte de formation diminue, mais la perte de validation augmente. Si vous voyez quelque chose comme ça, c’est un signe clair que votre modèle est surajusté : Il apprend très bien les données d’entraînement mais ne parvient pas à généraliser les connaissances aux données de test.
Comment éviter l’overfitting ?
La façon la plus simple d’éviter l’overfitting est de s’assurer que le nombre de paramètres indépendants dans votre ajustement est beaucoup plus petit que le nombre de points de données que vous avez. L’idée de base est que si le nombre de points de données est dix fois supérieur au nombre de paramètres, l’overfitting n’est pas possible.
Quelles sont les causes de l’overfitting ?
L’overfitting se produit lorsqu’un modèle apprend les détails et le bruit des données de formation au point d’avoir un impact négatif sur les performances du modèle sur les nouvelles données. Cela signifie que le bruit ou les fluctuations aléatoires des données d’apprentissage sont captés et appris comme des concepts par le modèle.
Comment réduire l’overfitting de XGBoost ?
Il y a en général deux façons de contrôler l’overfitting dans XGBoost :
- La première façon est de contrôler directement la complexité du modèle. Cela inclut max_depth , min_child_weight et gamma .
- La deuxième façon est d’ajouter de l’aléatoire pour rendre la formation robuste au bruit. Cela inclut subsample et colsample_bytree .
La validation croisée est-elle nécessaire pour la forêt aléatoire ?
Oui, la performance hors-sac pour une forêt aléatoire est très similaire à la validation croisée. Essentiellement, ce que vous obtenez est leave-one-out avec les forêts aléatoires de substitution utilisant moins d’arbres. Donc, si cela est fait correctement, vous obtenez un léger biais pessimiste.
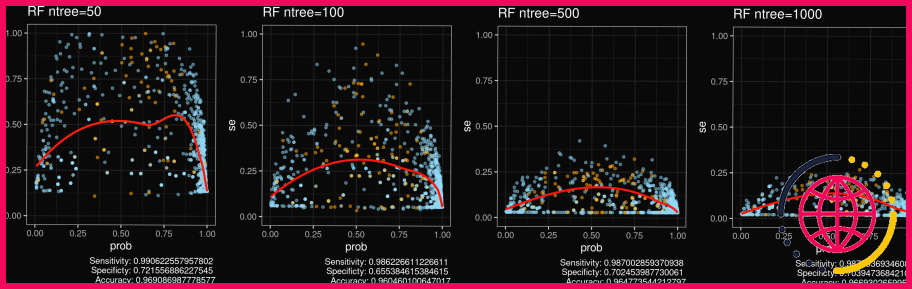
Comment la forêt aléatoire calcule-t-elle la probabilité ?
Dans le package Random Forest en passant le paramètre « type = prob » alors au lieu de nous donner la classe prédite du point de données on obtient la probabilité. Comment cette probabilité est-elle calculée ? Par défaut, la forêt aléatoire fait un vote majoritaire parmi tous ses arbres pour prédire la classe de tout point de données.
La forêt aléatoire peut-elle faire de l’apprentissage non supervisé ?
Par conséquent, si une matrice de dissimilarité peut être produite en utilisant Random Forest, nous pouvons mettre en œuvre avec succès l’apprentissage non supervisé. Les modèles trouvés dans le processus seront utilisés pour faire des clusters.
La forêt aléatoire est-elle un apprentissage profond ?
Quelle est la principale différence entre la forêt aléatoire et les réseaux neuronaux ? La forêt aléatoire et les réseaux neuronaux sont tous deux des techniques différentes qui apprennent différemment mais peuvent être utilisés dans des domaines similaires. La forêt aléatoire est une technique d’apprentissage automatique tandis que les réseaux neuronaux sont exclusifs à l’apprentissage profond.
Pourquoi la forêt aléatoire est-elle meilleure que la régression logistique ?
La régression logistique est plus performante lorsque le nombre de variables de bruit est inférieur ou égal au nombre de variables explicatives et la forêt aléatoire a un taux de vrais et faux positifs plus élevé lorsque le nombre de variables explicatives augmente dans un ensemble de données.
Les forêts aléatoires ont-elles besoin d’être élaguées ?
La forêt aléatoire est une technique d’apprentissage automatique supervisée d’ensemble. Pour un apprentissage et une classification efficaces de la forêt aléatoire, il est nécessaire de réduire le nombre d’arbres (élagage) dans la forêt aléatoire.