Lequel est le plus rapide : join ou lookup ?
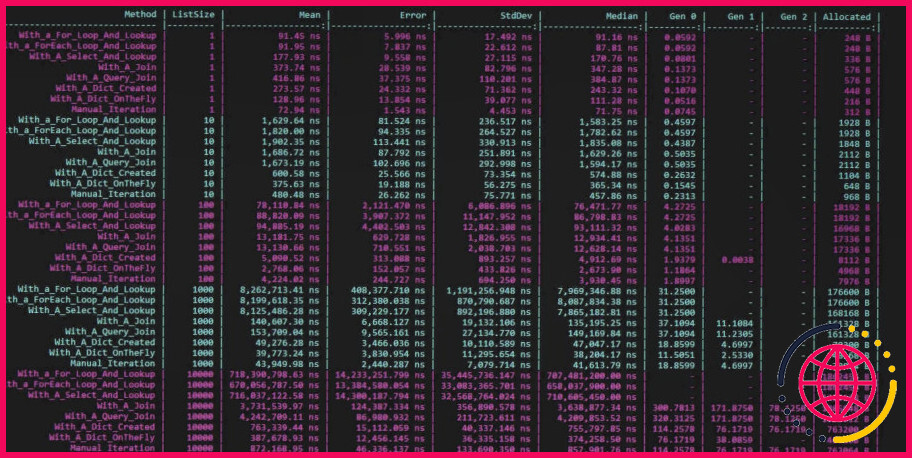
De nombreux facteurs doivent être pris en compte lorsque vous vous demandez quelle est la jointure ou la recherche la plus rapide. Le facteur le plus important est le type de données utilisé. Si le type de données est un entier, la recherche sera plus rapide. Si le type de données est une chaîne, la jointure sera plus rapide. La raison en est que les chaînes occupent plus d’espace que les entiers et nécessitent donc plus de temps pour être traitées. Un autre facteur à considérer est la taille de l’ensemble de données. Si l’ensemble de données est petit, la recherche sera plus rapide. Si l’ensemble de données est volumineux, la jointure sera plus rapide. En effet, la recherche nécessite moins de temps pour traiter un petit ensemble de données, tandis que la jointure nécessite moins de temps pour traiter un grand ensemble de données.
Dans le cas d’un fichier plat, généralement, le joiner trié est plus efficace que le lookup, car le joiner trié utilise des conditions de jointure et met en cache moins de lignes. Dans le cas d’une base de données, lookup peut être efficace si la base de données peut retourner rapidement des données triées et si la quantité de données est faible, car lookup peut créer un cache entier en mémoire.
Quelle est la différence entre Join et lookup ?
Quelle est la différence entre lookup,et join ? Pavan Kurapati (Trifacta, Inc.) Un lookup compare chaque valeur de la colonne sélectionnée avec les valeurs d’une colonne sélectionnée de l’ensemble de données cible. Une jointure est une opération standard pour fusionner les données de deux ensembles de données différents.
Quelle est la différence entre une transformation de type lookup et joiner ?
Joiner est utilisé pour joindre deux sources homogènes ou hétérogènes résidant à des endroits différents. Lookup est utilisé pour consulter les données. Joiner est une transformation active. La transformation Lookup est une transformation passive.
Quelle est la différence entre l’étape de Join merge et celle de lookup ?
L’étape Merge peut avoir un nombre quelconque de liens d’entrée, des liens de sortie uniques et le même nombre de liens de sortie de rejet que les liens d’entrée de mise à jour. Une fiche et un enregistrement de mise à jour sont fusionnés seulement si les deux ont les mêmes valeurs pour la clé fusionnée spécifiée. En d’autres termes, l’étape de fusion ne fait pas de recherche de plage.
Quelle est la différence entre lookup et merge join dans SSIS ?
Lookup et Merge join ces deux composants dans SSIS utilisés pour la jointure entre les deux Tables. Mais il y a une différence majeure. Lookup est utilisé pour comparer les données entre deux tables. Mais il renvoie uniquement la première ligne des lignes mises en correspondance.
Qu’est-ce que la jointure equi ?
Une jointure equi est un type de jointure qui combine des tables sur la base de valeurs correspondantes dans des colonnes spécifiées. Les noms des colonnes ne doivent pas nécessairement être les mêmes. La table résultante contient des colonnes répétées. Il est possible d’effectuer une equi join sur plus de deux tables.
Quelle est la différence entre la fusion et la jointure ?
La jointure et la fusion peuvent toutes les deux être utilisées pour combiner deux cadres de données mais la méthode de jointure combine deux cadres de données sur la base de leurs index alors que la méthode de fusion est plus polyvalente et nous permet de spécifier des colonnes à côté de l’index à joindre pour les deux cadres de données.
Combien de liens de rejet peut-on avoir avec l’étape de fusion ?
L’étape de fusion est une étape de traitement. Il peut avoir n’importe quel nombre de liens d’entrée, un seul lien de sortie, et le même nombre de liens de rejet qu’il y a de liens d’entrée de mise à jour. L’étage Merge est l’un des trois étages qui rejoignent les tables en fonction des valeurs des colonnes clés.
Combien de types de jointure sont possibles dans l’étape de jointure ?
Il a un nombre quelconque de liens d’entrée et un seul lien de sortie. L’étage peut effectuer l’une des quatre opérations de jointure suivantes : Inner transfère les enregistrements des ensembles de données d’entrée dont les colonnes clés contiennent des valeurs égales vers l’ensemble de données de sortie.
Quels sont les deux types de lookups ?
Il existe deux formes de Lookup : Vecteur et Tableau. La forme vectorielle de la fonction LOOKUP recherchera une ligne ou une colonne de données pour une valeur spécifiée et obtiendra ensuite les données de la même position dans une autre ligne ou colonne.
Peut-on utiliser join dans lookup override ?
2 Réponses. Oui tous les types de jointures sont possibles dans la transformation Lookup en utilisant SQL override.
Lookup est-elle une transformation active ?
Lorsque vous configurez la transformation Lookup pour retourner une seule ligne, la transformation Lookup est une transformation passive. Lorsque vous configurez la transformation Lookup pour retourner plusieurs lignes, la transformation Lookup est une transformation active. Vous pouvez utiliser plusieurs transformations Lookup dans un mapping.
Quels sont les types de transformation Lookup ?
Types de transformations Lookup
- Connectées ou non connectées : Elles diffèrent par la façon dont la sortie est reçue.
- Lookup via un fichier plat ou relationnel : Après avoir créé Lookup Transformation, nous pouvons effectuer des recherches soit sur un fichier plat, soit sur des tables relationnelles.
- Cached ou Uncached :
Quel type de jointure est le lookup ?
Le type de jointure par défaut de la transformation lookup est left-outer join dans informatica.
Quelle est la différence entre le lookup normal et le sparse lookup ?
Le sparse lookup frappe directement la base de données. Si les données du flux d’entrée sont moins nombreuses et les données de référence sont plus comme 1:100 ou plus, dans ces cas, sparse lookup est meilleur. Sparse Lookup, nous ne pouvons avoir qu’un seul lien de référence. Sparse lookup,nous pouvons seulement utiliser pour Oracle et DB2.
Comment utiliser le lookup non connecté ?
Transformation de lookup non connecté dans un exemple Informatica.
- Étape 1 : création de la définition de source pour la transformation Lookup non connectée dans Informatica.
- Étape 2 : création d’une définition cible pour la transformation Lookup non connectée d’Informatica.
- Étape 3 : créer un mappage de transformation de recherche non connectée Informatica.
Qu’est-ce que l’étape de jonction ?
L’étape de jonction est une étape de traitement qui effectue des opérations de jonction sur deux ou plusieurs ensembles de données en entrée de l’étape, puis sort l’ensemble de données résultant. L’étage de jonction est un étage de traitement. Il effectue des opérations de jointure sur deux ou plusieurs ensembles de données en entrée de l’étage, puis sort l’ensemble de données résultant.
Qu’est-ce que l’étape de fusion dans Datastage ?
L’étape de fusion est une étape de traitement. Elle peut avoir un nombre quelconque de liens d’entrée, un seul lien de sortie et le même nombre de liens de rejet que de liens d’entrée de mise à jour. L’étape Merge combine un ensemble de données de base avec un ou plusieurs ensembles de données de mise à jour.
L’étape Join peut-elle avoir un lien Reject dans Datastage ?
Contrairement aux étapes Join et Lookup, l’étape Merge vous permet de spécifier plusieurs liens de rejet. Vous pouvez acheminer les lignes de lien de mise à jour qui ne correspondent pas à une ligne maître vers un lien de rejet spécifique à ce lien. Vous devez avoir le même nombre de liens de rejet que de liens de mise à jour.
Quelle est l’utilité de modify stage dans Datastage ?
L’étape Modify modifie le schéma d’enregistrement de son jeu de données d’entrée. L’ensemble de données modifié est ensuite sorti. Vous pouvez supprimer ou conserver des colonnes du schéma, ou modifier le type d’une colonne. L’étape Modifier est une étape de traitement.
Qu’est-ce que le lookup Datastage ?
L’étape Lookup est une étape de traitement qui est utilisée pour effectuer des opérations de consultation sur un ensemble de données lues en mémoire à partir de n’importe quelle autre étape de travail parallèle qui peut sortir des données. Lorsque l’étage Lookup lit chaque ligne, il utilise la clé pour rechercher l’état dans la table de consultation.
Qu’est-ce qu’un fichier séquentiel dans Datastage ?
L’étape Sequential File est une étape de fichier qui vous permet de lire des données à partir de ou d’écrire des données un ou plusieurs fichiers plats. L’étape peut avoir un seul lien d’entrée ou un seul lien de sortie, et un seul lien de rejet. Vous pouvez spécifier que des fichiers uniques peuvent être lus par plusieurs nœuds.
Pourquoi la fusion est utilisée dans Oracle ?
L’instruction MERGE a été introduite dans Oracle 9i pour insérer ou mettre à jour conditionnellement des données en fonction de leur présence, un processus également appelé « upsert ». L’instruction MERGE réduit les balayages de table et peut effectuer l’opération en parallèle si nécessaire.
Qu’est-ce qu’une jointure de fusion gauche ?
Une jointure gauche, ou fusion gauche, conserve chaque ligne du cadre de données de gauche. Résultat de la jointure gauche ou de la fusion gauche de deux dataframes dans Pandas. Les lignes de la dataframe de gauche qui n’ont pas de valeur de jointure correspondante dans la dataframe de droite sont laissées avec des valeurs NaN.
Quelle est la rapidité de pandas join ?
Le temps d’exécution + récupération varie entre 310-340 ms pour les trois types de jointure, avec et sans index, pour le cas many-to-one. Le cas many-to-many varie entre 420-490 ms, alors que pandas est à 22-25ms ! Donc pandas surpasse toujours significativement SQLite3 (même avec des index SQL comme dans ces benchmarks).