Comment analyser des documents avec LangChain et l’API OpenAI

Extraire des informations de documents et de données est essentiel pour prendre des décisions éclairées. Cependant, des problèmes de confidentialité se posent lorsqu’il s’agit d’informations sensibles. LangChain, en combinaison avec l’API OpenAI, vous permet d’analyser vos documents locaux sans avoir à les télécharger en ligne.
Ils y parviennent en conservant vos données localement, en utilisant les embeddings et la vectorisation pour l’analyse, et en exécutant les processus dans votre environnement. OpenAI n’utilise pas les données soumises par les clients via son API pour former ses modèles ou améliorer ses services.
Mise en place de votre environnement
Créez un nouvel environnement virtuel Python. Cela permettra de s’assurer qu’il n’y a pas de conflit de version de bibliothèque. Exécutez ensuite la commande de terminal suivante pour installer les bibliothèques requises.
Voici une description de l’utilisation de chaque bibliothèque :
- LangChain: Vous l’utiliserez pour créer et gérer des chaînes linguistiques pour le traitement et l’analyse de textes. Il fournira des modules pour le chargement de documents, le découpage de textes, l’intégration et le stockage de vecteurs.
- OpenAI: Vous l’utiliserez pour exécuter des requêtes et obtenir des résultats à partir d’un modèle de langage.
- tiktoken: Vous l’utiliserez pour compter le nombre de jetons (unités de texte) dans un texte donné. Cela permet de garder une trace du nombre de tokens lorsque vous interagissez avec l’API OpenAI qui facture en fonction du nombre de tokens que vous utilisez.
- FAISS: Vous l’utiliserez pour créer et gérer un magasin de vecteurs, permettant la récupération rapide de vecteurs similaires basés sur leurs embeddings.
- PyPDF: Cette bibliothèque extrait le texte des fichiers PDF. Elle permet de charger des fichiers PDF et d’en extraire le texte pour un traitement ultérieur.
Une fois toutes les bibliothèques installées, votre environnement est maintenant prêt.
Obtenir une clé API OpenAI
Lorsque vous faites des demandes à l’API OpenAI, vous devez inclure une clé API dans la demande. Cette clé permet au fournisseur d’API de vérifier que les demandes proviennent d’une source légitime et que vous disposez des autorisations nécessaires pour accéder à ses fonctionnalités.
Pour obtenir une clé d’API OpenAI, procédez comme suit plateforme OpenAI.
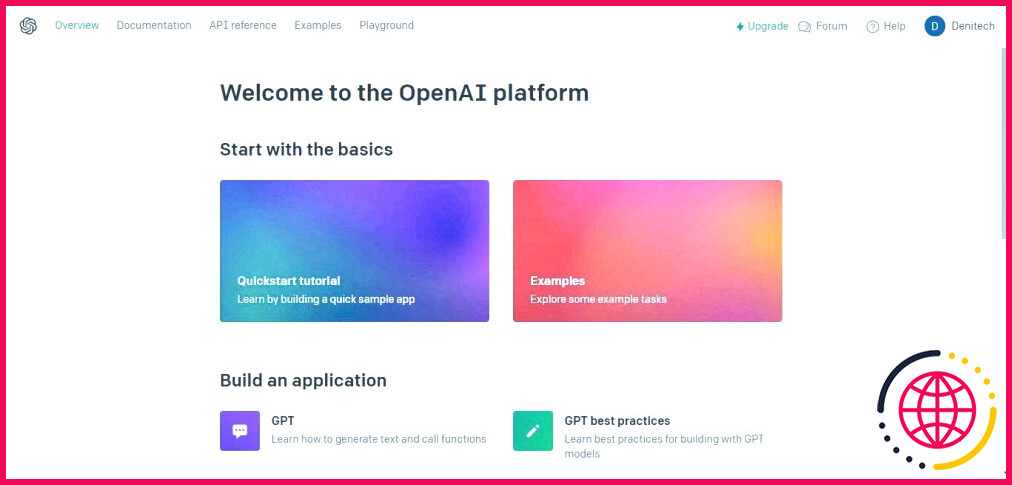
Ensuite, sous le profil de votre compte en haut à droite, cliquez sur Voir les clés API. Les clés API s’affiche.
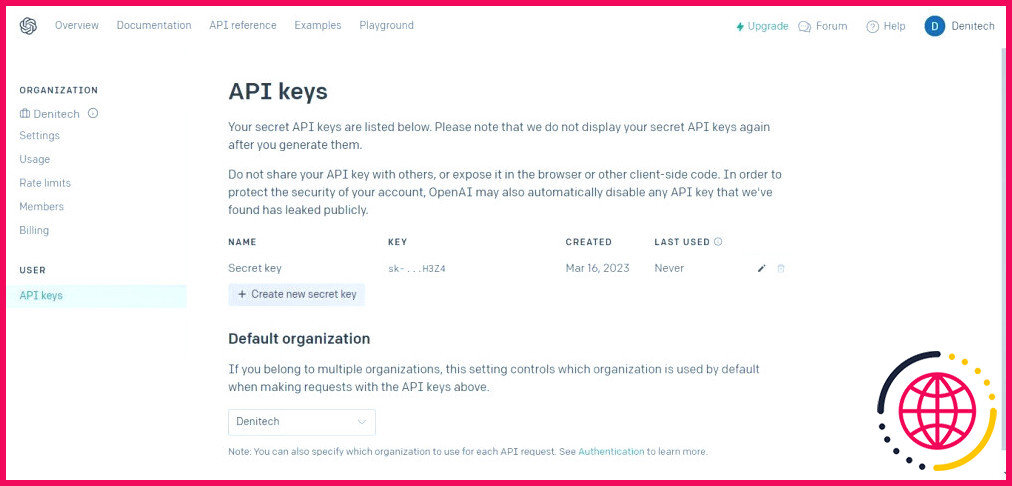
Cliquez sur la Créer un nouveau secret clé . Nommez votre clé et cliquez sur Créer une nouvelle clé secrète. OpenAI générera votre clé API que vous devrez copier et conserver en lieu sûr. Pour des raisons de sécurité, vous ne pourrez pas la consulter à nouveau via votre compte OpenAI. Si vous perdez cette clé secrète, vous devrez en générer une nouvelle.
Le code source complet est disponible dans un dépôt GitHub.
Importer les bibliothèques nécessaires
Pour pouvoir utiliser les bibliothèques installées dans votre environnement virtuel, vous devez les importer.
Notez que vous importez les bibliothèques de dépendance de LangChain. Cela vous permet d’utiliser des fonctionnalités spécifiques du framework LangChain.
Chargement du document pour analyse
Commencez par créer une variable qui contient votre clé API. Vous utiliserez cette variable plus loin dans le code pour l’authentification.
Il n’est pas recommandé de coder en dur votre clé API si vous prévoyez de partager votre code avec des tiers. Pour le code de production que vous souhaitez distribuer, utilisez plutôt une variable d’environnement.
Ensuite, créez une fonction qui charge un document. La fonction doit charger un fichier PDF ou un fichier texte. Si le document n’est ni l’un ni l’autre, la fonction doit générer une erreur de type ValueError.
Après avoir chargé les documents, créez un fichier CharacterTextSplitter. Ce séparateur divisera les documents chargés en morceaux plus petits en fonction des caractères.
Le fractionnement du document permet de s’assurer que les morceaux ont une taille gérable et qu’ils sont toujours liés à un certain contexte de chevauchement. Cela est utile pour des tâches telles que l’analyse de texte et la recherche d’informations.
Interroger le document
Vous avez besoin d’un moyen d’interroger le document téléchargé pour en tirer des informations. Pour ce faire, créez une fonction qui prend un fichier requête et une chaîne retriever en entrée. Il crée ensuite un AQ Récupération à l’aide de l’instance récupérateur et une instance du modèle de langage OpenAI.
Cette fonction utilise l’instance QA créée pour exécuter la requête et imprimer le résultat.
Création de la fonction principale
La fonction principale contrôlera le déroulement général du programme. Elle prend en compte le nom de fichier d’un document saisi par l’utilisateur et charge ce document. Elle crée ensuite un OpenAIEmbeddings pour les éléments incorporés et construire une instance magasin de vecteurs basé sur les documents chargés et les intégrés. Enregistrez ce magasin de vecteurs dans un fichier local.
Ensuite, chargez le magasin de vecteurs persistants à partir du fichier local. Entrez ensuite dans une boucle où l’utilisateur peut saisir des requêtes. Les principal transmet ces requêtes à la fonction query_pdf avec le récupérateur du magasin de vecteurs persistants. La boucle se poursuit jusqu’à ce que l’utilisateur saisisse « exit ».
Les embeddings capturent les relations sémantiques entre les mots. Les vecteurs sont une forme de représentation des morceaux de texte.
Ce code convertit les données textuelles du document en vecteurs à l’aide des embeddings générés par OpenAIEmbeddings. Il indexe ensuite ces vecteurs à l’aide de FAISS pour une récupération et une comparaison efficaces des vecteurs similaires. C’est ce qui permet l’analyse du document téléchargé.
Enfin, utilisez la construction __name__ == »__main__ » pour appeler la fonction principale si un utilisateur exécute le programme de manière autonome :
Cette application est une application en ligne de commande. En tant qu’extension, vous pouvez utiliser Streamlit pour ajouter une interface web à l’application.
Analyse de documents
Pour effectuer une analyse de document, stockez le document que vous souhaitez analyser dans le même dossier que votre projet, puis exécutez le programme. Il vous demandera le nom du document que vous souhaitez analyser. Saisissez son nom complet, puis entrez les requêtes que le programme doit analyser.
La capture d’écran ci-dessous montre les résultats de l’analyse d’un PDF.
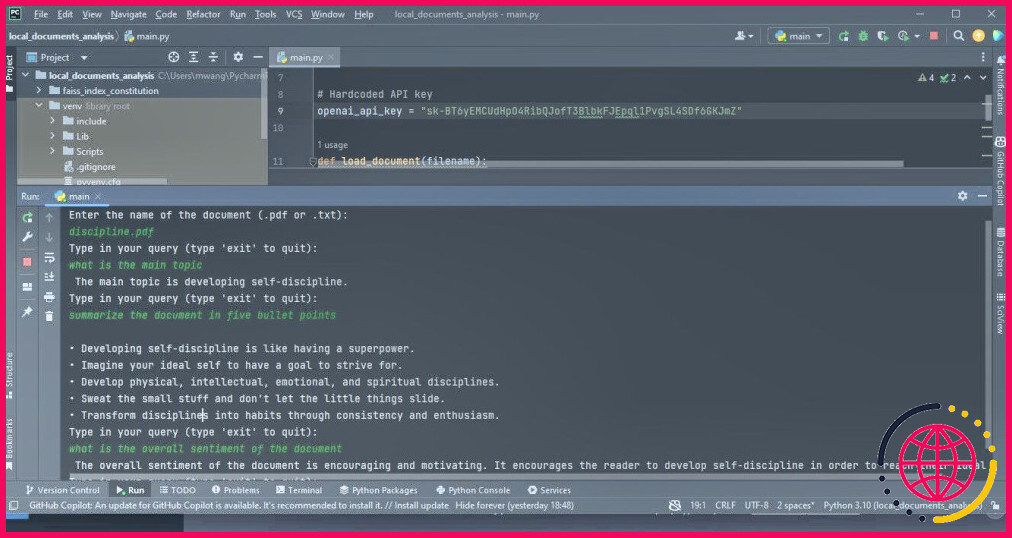
La sortie suivante montre les résultats de l’analyse d’un fichier texte contenant du code source.
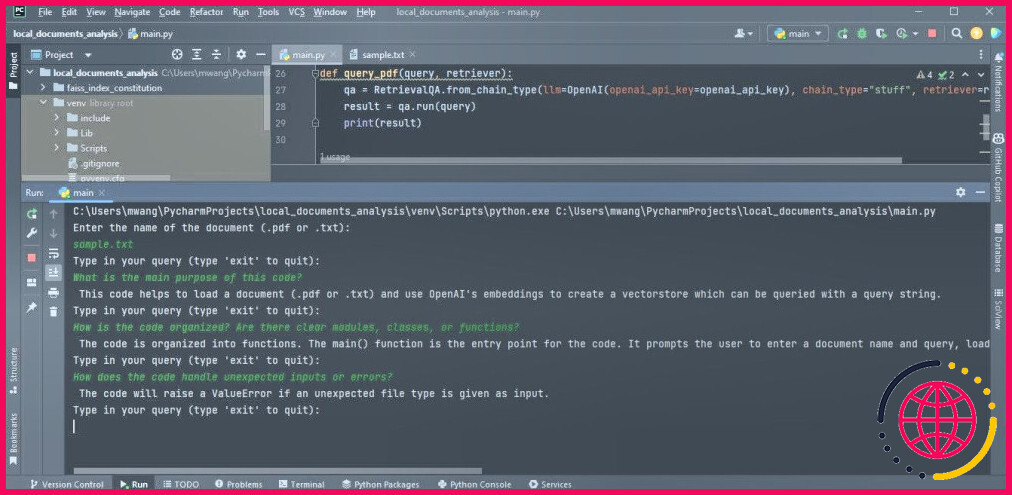
Assurez-vous que les fichiers que vous souhaitez analyser sont au format PDF ou texte. Si vos documents sont dans d’autres formats, vous pouvez les convertir au format PDF à l’aide d’outils en ligne.
Comprendre la technologie des grands modèles linguistiques
LangChain simplifie la création d’applications utilisant de grands modèles linguistiques. Cela signifie également qu’il fait abstraction de ce qui se passe dans les coulisses. Pour comprendre exactement comment fonctionne l’application que vous créez, vous devez vous familiariser avec la technologie qui sous-tend les grands modèles de langage.