Les 7 algorithmes d’apprentissage profond incontournables

Le domaine de l’intelligence artificielle (IA) a connu une croissance rapide ces derniers temps, ce qui a conduit au développement d’algorithmes d’apprentissage profond. Avec le lancement d’outils d’IA tels que DALL-E et OpenAI, l’apprentissage profond s’est imposé comme un domaine de recherche clé. Cependant, avec l’abondance des algorithmes disponibles, il peut être difficile de savoir lesquels sont les plus cruciaux à comprendre.
Plongez dans le monde fascinant de l’apprentissage profond et explorez les principaux algorithmes indispensables à la compréhension de l’intelligence artificielle.
1. Réseaux neuronaux convolutifs (CNN)
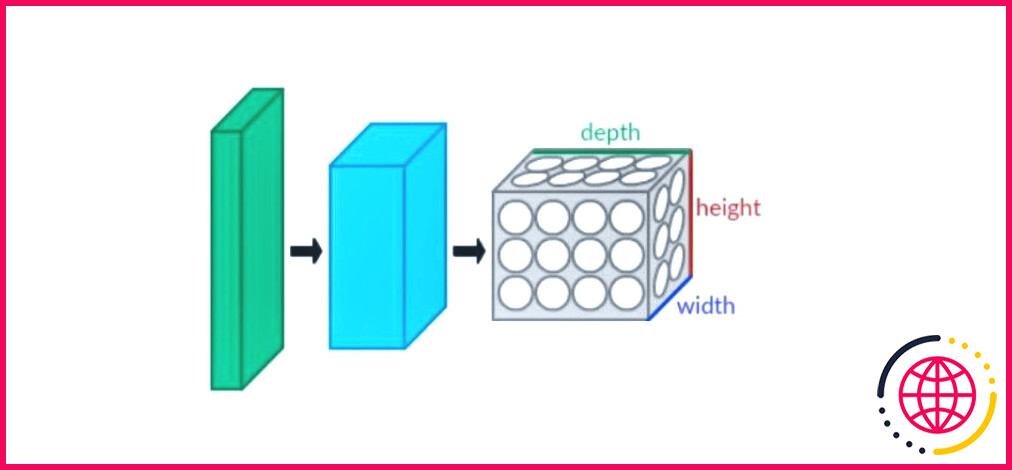 Crédit photo : Aphex34/Wikipédia
Crédit photo : Aphex34/Wikipédia
Les réseaux neuronaux convolutifs (CNN), également connus sous le nom de ConvNets, sont des réseaux neuronaux qui excellent dans la détection d’objets, la reconnaissance d’images et la segmentation. Ils utilisent plusieurs couches pour extraire les caractéristiques des données disponibles. Les CNN sont principalement constitués de quatre couches :
- Couche de convolution
- Unité linéaire rectifiée (ReLU)
- Couche de mise en commun
- Couche entièrement connectée
Ces quatre couches fournissent un mécanisme de fonctionnement au réseau. La couche de convolution est la première couche des CNN, qui filtre les caractéristiques complexes des données. Ensuite, la ReLU cartographie les données pour former le réseau. Ensuite, le processus envoie la carte à la couche de mise en commun, qui réduit l’échantillonnage et convertit les données en 2D en un tableau linéaire. Enfin, la couche entièrement connectée forme une matrice linéaire aplatie utilisée comme entrée pour détecter des images ou d’autres types de données.
2. Réseaux de croyance profonds
Les réseaux de croyance profonds (DBN) sont une autre architecture populaire pour l’apprentissage profond qui permet au réseau d’apprendre des modèles dans les données avec des caractéristiques d’intelligence artificielle. Ils sont idéaux pour des tâches telles que les logiciels de reconnaissance faciale et la détection des caractéristiques des images.
Le mécanisme DBN implique différentes couches de machines de Boltzmann restreintes (RBM), qui est un réseau neuronal artificiel qui aide à l’apprentissage et à la reconnaissance de modèles. Les couches du DBN suivent l’approche descendante, permettant la communication à travers le système, et les couches RBM fournissent une structure robuste qui peut classer les données sur la base de différentes catégories.
3. Réseaux neuronaux récurrents (RNN)

Les réseaux neuronaux récurrents (RNN) sont un algorithme d’apprentissage profond très répandu, avec un large éventail d’applications. Le réseau est surtout connu pour sa capacité à traiter des données séquentielles et à concevoir des modèles de langage. Il peut apprendre des modèles et prédire des résultats sans les mentionner dans le code. Par exemple, le moteur de recherche Google utilise le RNN pour compléter automatiquement les recherches en prédisant les recherches pertinentes.
Le réseau fonctionne avec des couches de nœuds interconnectés qui aident à mémoriser et à traiter les séquences d’entrée. Il peut ensuite traiter ces séquences pour prédire automatiquement les résultats possibles. En outre, les RNN peuvent apprendre à partir d’entrées antérieures, ce qui leur permet d’évoluer à mesure qu’ils sont exposés. Par conséquent, les RNN sont idéaux pour la modélisation du langage et la modélisation séquentielle.
4. Réseaux de mémoire à long terme (LSTM)
Les réseaux de mémoire à long terme (LSTM) sont un type de réseau neuronal récurrent (RNN) qui se distingue des autres par sa capacité à travailler avec des données à long terme. Ils ont une mémoire et des capacités de prédiction exceptionnelles, ce qui rend les LSTM idéaux pour des applications telles que les prédictions de séries temporelles, le traitement du langage naturel (NLP), la reconnaissance vocale et la composition musicale.
Les réseaux LSTM sont constitués de blocs de mémoire disposés selon une structure en chaîne. Ces blocs stockent des informations et des données pertinentes susceptibles d’informer le réseau à l’avenir, tout en supprimant les données inutiles pour rester efficace.
Pendant le traitement des données, la LSTM change d’état de cellule. Tout d’abord, il supprime les données non pertinentes par le biais de la couche sigmoïde. Ensuite, il traite les nouvelles données, évalue les parties nécessaires et remplace les données non pertinentes précédentes par les nouvelles données. Enfin, il détermine la sortie en fonction de l’état actuel de la cellule qui a filtré les données.
La capacité à traiter des données à long terme distingue les LSTM des autres RNN, ce qui les rend idéales pour les applications qui requièrent de telles capacités.
5. Réseaux adverbiaux génératifs
Les réseaux adversoriels génératifs (GAN) sont un type d’algorithme d’apprentissage profond qui prend en charge l’IA générative. Ils sont capables d’apprentissage non supervisé et peuvent générer des résultats par eux-mêmes en s’entraînant à travers des ensembles de données spécifiques pour créer de nouvelles instances de données.
Le modèle GAN se compose de deux éléments clés : un générateur et un discriminateur. Le générateur est entraîné à créer de fausses données sur la base de son apprentissage. En revanche, le discriminateur est entraîné à vérifier la sortie pour détecter les fausses données ou les erreurs et à rectifier le modèle en conséquence.
Les GAN sont largement utilisés pour la génération d’images, notamment pour améliorer la qualité graphique des jeux vidéo. Ils sont également utiles pour améliorer les images astronomiques, simuler les lentilles gravitationnelles et générer des vidéos. Les GAN restent un sujet de recherche populaire dans la communauté de l’IA, car leurs applications potentielles sont vastes et variées.
6. Perceptrons multicouches
Le perceptron multicouche (MLP) est un autre algorithme d’apprentissage profond, qui est également un réseau neuronal avec des nœuds interconnectés en plusieurs couches. Le MLP maintient une dimension de flux de données unique de l’entrée à la sortie, ce qui est connu sous le nom de feedforward. Il est couramment utilisé pour la classification d’objets et les tâches de régression.
La structure du MLP comprend plusieurs couches d’entrée et de sortie, ainsi que plusieurs couches cachées, afin d’effectuer des tâches de filtrage. Chaque couche contient plusieurs neurones qui sont interconnectés les uns avec les autres, même d’une couche à l’autre. Les données sont d’abord transmises à la couche d’entrée, d’où elles progressent dans le réseau.
Les couches cachées jouent un rôle important en activant des fonctions telles que les ReLU, la sigmoïde et le tanh. Ensuite, elles traitent les données et génèrent une sortie sur la couche de sortie.
Ce modèle simple mais efficace est utile pour la reconnaissance vocale et vidéo et les logiciels de traduction. Les MLP ont gagné en popularité en raison de leur conception simple et de leur facilité de mise en œuvre dans divers domaines.
7. Autoencodeurs
Les autoencodeurs sont un type d’algorithme d’apprentissage profond utilisé pour l’apprentissage non supervisé. C’est un modèle feedforward avec un flux de données unidirectionnel, similaire au MLP. Les autoencodeurs sont alimentés en entrée et la modifient pour créer une sortie, ce qui peut être utile pour la traduction des langues et le traitement des images.
Le modèle se compose de trois éléments : le codeur, le code et le décodeur. Ils codent l’entrée, la redimensionnent en unités plus petites, puis la décodent pour générer une version modifiée. Cet algorithme peut être appliqué dans divers domaines, tels que la vision par ordinateur, le traitement du langage naturel et les systèmes de recommandation.
Choisir le bon algorithme d’apprentissage profond
Pour choisir l’approche d’apprentissage profond appropriée, il est crucial de prendre en compte la nature des données, le problème posé et le résultat souhaité. En comprenant les principes fondamentaux et les capacités de chaque algorithme, vous pourrez prendre des décisions éclairées.
Le choix du bon algorithme peut faire toute la différence dans la réussite d’un projet. Il s’agit d’une étape essentielle pour construire des modèles d’apprentissage profond efficaces.
S’abonner à notre newsletter
Quels sont les algorithmes les plus importants dans l’apprentissage profond ?
Que vous soyez débutant ou professionnel, ces trois principaux algorithmes d’apprentissage profond vous aideront à résoudre des problèmes compliqués liés à l’apprentissage profond : CNN ou réseaux neuronaux convolutifs, LSTM ou réseaux de mémoire à long terme à court terme et RNN ou réseaux neuronaux récurrents (RNN).
Quels sont les 10 principaux algorithmes d’apprentissage automatique ?
Quels sont les 10 algorithmes d’apprentissage automatique les plus populaires ? Régression linéaire.Régression logistique.Arbre de décision.Algorithme SVM.Algorithme Naive Bayes.Algorithme KNN.K-means.Algorithme Random forest.
- Régression linéaire.
- Régression logistique.
- Arbre de décision.
- Algorithme SVM.
- Algorithme Naive Bayes.
- Algorithme KNN.
- K-means.
- Algorithme de la forêt aléatoire.
Quels sont les 4 principaux algorithmes ?
Il existe quatre types d’algorithmes d’apprentissage automatique : supervisé, semi-supervisé, non supervisé et de renforcement.
Quels sont les derniers algorithmes d’apprentissage profond ?
Les 10 meilleurs algorithmes d’apprentissage profond que vous devez connaître en 2023. Réseaux de mémoire à long terme (LSTM) Autoencodeurs. Cartes auto-organisatrices (SOM) Apprentissage par renforcement profond. Réseaux neuronaux récurrents (RNN) Réseaux de capsules. Réseaux adversoriels génératifs (GAN) Réseaux à fonction de base radicale (RBFN)
- Réseaux à mémoire à long terme (LSTM)
- Autoencodeurs.
- Cartes auto-organisatrices (SOM)
- Apprentissage par renforcement profond.
- Réseaux neuronaux récurrents (RNN)
- Réseaux de capsules.
- Réseaux adversoriels génératifs (GAN)
- Réseaux à fonction de base radicale (RBFN)