Les 9 meilleurs outils Python ETL pour répondre à vos besoins en données

Les types de données au cœur des connaissances de l’entreprise, et 2022 ne feront certainement pas exception à cette règle. Python est en fait devenu l’appareil préféré pour les émissions et l’analyse d’informations. De plus, le framework Python ETL soutient les canaux d’information, stabilisant ainsi de nombreux sous-secteurs dédiés à la collecte de données, à la discussion, à l’analyse, entre autres.
Connaissant les fonctionnalités de Python ainsi que son utilisation dans la facilitation ETL, vous pouvez comprendre comment cela peut faciliter le travail d’un expert en données.
Qu’est-ce qu’ETL ?
ETL signifie Extraire, Charger et aussi Transformer. Il s’agit d’un processus séquentiel consistant à extraire des informations de plusieurs ressources de données, à les modifier en fonction des demandes, ainsi qu’à les compresser directement dans leur destination finale. Ces emplacements peuvent varier d’une base de données de stockage, d’un périphérique de BI, d’une installation de stockage d’informations, et bien plus encore.
Le pipeline ETL collecte des informations à partir de procédures intra-business, de systèmes clients externes, de fournisseurs, ainsi que de nombreuses autres ressources d’informations connectées. Les données collectées sont filtrées par le système, modifiées et échangées sous une forme claire, avant d’être utilisées pour l’analyse.
La structure Python ETL a longtemps fonctionné comme l’un des langages les mieux adaptés pour exécuter des programmes mathématiques et analytiques complexes.
Par conséquent, il n’est pas surprenant que la bibliothèque foisonnante de Python ainsi que la documentation soient chargées de donner naissance à quelques-uns des appareils ETL les plus fiables actuellement disponibles.
Meilleurs outils Python ETL à apprendre
Le marché est inondé d’outils ETL, dont chacun fournit un ensemble varié de capacités à l’utilisateur final. Néanmoins, le respect de la liste de contrôle couvre quelques-uns des meilleurs outils Python ETL pour vous simplifier la vie et la rendre plus fluide.
1. Bulles
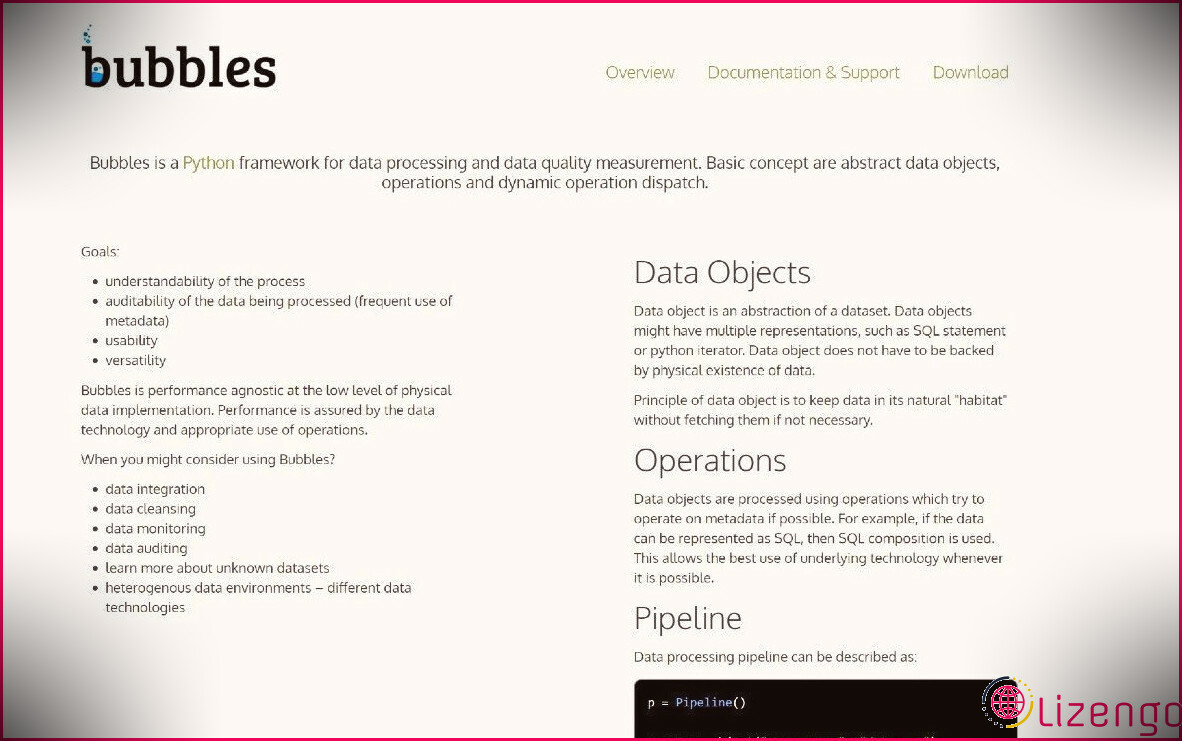
Bubbles est une structure Python ETL utilisée pour gérer les informations ainsi que pour maintenir le pipeline ETL. Il traite le canal de traitement des données en tant que graphique routé qui facilite l’agrégation, le filtrage, la comptabilité, les comparaisons et la conversion des données.
En tant qu’outil Python ETL, Bubbles vous permet de rendre les données très flexibles, de sorte qu’elles puissent être utilisées pour conduire des analyses dans plusieurs cas d’utilisation de service.
Le cadre d’informations Bubbles traite les actifs de données comme des objets, y compris les informations CSV vers les éléments SQL, les itérateurs Python et même les éléments API des sites de médias sociaux. Vous pouvez compter sur lui pour progresser au fur et à mesure qu’il découvre des ensembles de données abstraits et non identifiés, ainsi que des environnements/technologies de données variés.
2. Metl
Metl ou Mito-ETL est une plate-forme d’avancement Python ETL à prolifération rapide utilisée pour établir des éléments de code sur mesure. Ces éléments de code peuvent varier des assimilations d’informations SGBDR, des assimilations de données de documents plats, des combinaisons d’informations basées sur des API/services, ainsi que des intégrations d’informations Pub/Sub (basées sur des files d’attente).
Metl permet aux membres non techniques de votre entreprise de développer plus facilement des options rapides, basées sur Python et à faible code. Cet appareil contient différents types de données et génère des services stables pour la logistique de plusieurs données à l’aide de boîtiers.
3. Apache Spark
Apache Spark est un appareil ETL exceptionnel pour l’automatisation basée sur Python pour les particuliers et les entreprises qui traitent des informations en continu. La croissance de la quantité de données est proportionnelle à l’évolutivité de l’entreprise, ce qui rend l’automatisation nécessaire et implacable avec Spark ETL.
La gestion des données au niveau du démarrage est simple ; néanmoins, la procédure est ennuyeuse, éprouvante et sujette aux erreurs manuelles, surtout lorsque votre entreprise se développe.
Spark propose des solutions instantanées pour les données JSON semi-structurées provenant de sources disparates, car il transforme les types de données en informations compatibles SQL. En conjonction avec la conception des informations Snowflake, le tuyau Spark ETL fonctionne comme une main dans la main.
4. Petl
Petl est un moteur de traitement de flux idéal pour traiter des données mixtes de qualité supérieure. Cet outil Python ETL aide les analystes de données avec peu ou pas d’expérience en codage à évaluer rapidement les ensembles de données enregistrés au format CSV, XML, JSON, ainsi que de nombreux autres styles de données. Vous pouvez organiser, vous inscrire et regrouper les améliorations avec très peu d’effort.
Malheureusement, Petl ne peut pas vous aider avec des ensembles de données complexes et spécifiques. Néanmoins, il s’agit de l’un des meilleurs dispositifs pilotés par Python pour structurer et accélérer les parties de code du pipeline ETL.
5. Riko
Riko est un substitut approprié pour Yahoo Pipes. Elle reste idéale pour les start-up ayant un savoir-faire technologique réduit.
Il s’agit d’une collection de tuyaux ETL conçue par Python, principalement conçue pour traiter les flux d’informations non structurés. Riko se vante d’API synchrones-asynchrones, d’une petite empreinte de processeur, ainsi que d’une assistance indigène RSS/Atom.
Riko permet aux groupes de mener des opérations dans une mise en œuvre identique. Le moteur de gestion de flux de la plate-forme vous aide à créer des flux RSS contenant du son et des textes de blog. C’est même avec la capacité d’analyser des ensembles de données CSV/XML/JSON/HTML, qui font partie intégrante de la connaissance de l’organisation.
6. Luigi
Luigi est un outil de framework Python ETL léger et fonctionnel qui prend en charge la visualisation des données, la combinaison CLI, l’administration du processus de données, le suivi des réussites/échecs des travaux ETL, ainsi que la résolution des dépendances.
Cet appareil à multiples facettes suit une tâche simple ainsi qu’une méthode basée sur des cibles, où chaque cible tient votre groupe par la main via la tâche suivante et l’exécute également instantanément.
Pour un appareil ETL open source, Luigi traite efficacement les problèmes complexes liés aux données. L’appareil localise l’approbation du service de musique à la demande Spotify pour accumuler et partager une fois par semaine des références de listes de lecture de chansons aux clients.
sept. Flux d’air
Airflow a attiré une légion constante de clients parmi les ingénieurs de données d’affaires et compétents en tant qu’outil de configuration et d’entretien des canaux de données.
L’interface Web Airflow facilite l’automatisation de routine, gère les processus et les exécute avec la CLI inhérente. La boîte à outils open source peut vous aider à automatiser les opérations d’information, à organiser vos tuyaux ETL pour une orchestration fiable, ainsi qu’à les gérer à l’aide de graphes acryliques dirigés (DAG).
Le dispositif des coûts est une offre gratuite du tout-puissant Apache. C’est l’outil le plus efficace de votre collection pour une combinaison simple avec votre structure ETL existante.
8. bonobos
Bonobo est un déploiement de pipeline ETL open source basé sur Python ainsi qu’un outil de suppression d’informations. Vous pouvez profiter de son CLI pour extraire des données de SQL, CSV, JSON, XML, ainsi que de nombreuses autres sources.
Bonobo traite des schémas d’information semi-structurés. Sa spécialisation dépend de son utilisation des conteneurs Docker pour la mise en œuvre des tâches ETL. Cependant, son véritable USP dépend de son extension SQLAlchemy et également du traitement parallèle des sources de données.
9. les pandas
Pandas est une collection de traitement d’ensembles ETL avec des structures d’informations écrites en Python ainsi que des outils d’analyse.
Les Pandas de Python accélèrent le traitement des données non structurées/semi-structurées. Les bibliothèques sont utilisées pour des tâches ETL de faible intensité, notamment le nettoyage des données et le traitement de petits ensembles de données structurés après la transformation à partir de collections semi-ou non structurées.
Choisir les outils ETL les plus efficaces
Il n’y a pas de dispositif ETL idéal pour tous. Les personnes et les entreprises doivent prendre en compte la qualité de leurs données, leur structure, leurs contraintes de temps et l’accessibilité des compétences avant de sélectionner leurs outils.
Chacun des appareils détaillés ci-dessus peut vous aider longuement à atteindre vos objectifs ETL.