Comment fonctionne la réplication mysql maître-esclave ?
La réplication fonctionne comme suit : Chaque fois que la base de données du maître est modifiée, la modification est écrite dans un fichier, appelé journal binaire, ou binlog. Le esclave possède un autre thread, appelé SQL thread, qui lit continuellement le journal de relais et applique les modifications au serveur esclave .
Ainsi, simplement, qu’est-ce que la réplication maître-esclave dans MySQL ?
La réplication MySQL est un processus qui vous permet de maintenir facilement plusieurs copies d’une MySQL de données en les faisant copier automatiquement d’une base de données master vers une base de données slave .
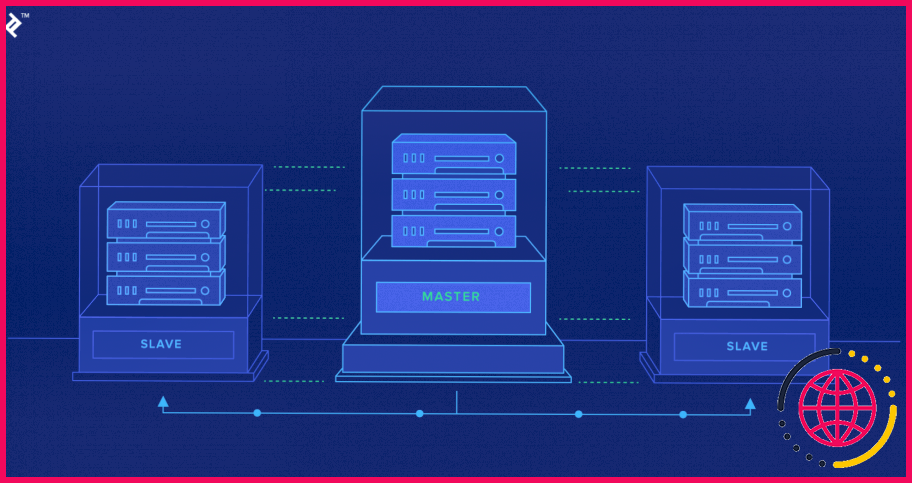
De même, comment fonctionnent les bases de données maître-esclave ? La réplication maître – esclave permet aux données d’un serveur de base (le maître ) de être répliquées vers un ou plusieurs autres serveurs de base (les esclaves). Le maître enregistre les mises à jour, qui se répercutent ensuite vers les esclaves. Dans cet environnement, toutes les écritures et mises à jour doivent avoir lieu sur le serveur master .
A cet égard, MySQL supporte-t-il la réplication ?
2.1. MySQL supporte également la réplication semi-synchrone, où le maître ne confirme pas les transactions au client avant qu’au moins un esclave ait copié la modification dans son journal de relais, et l’ait vidée sur le disque.
Comment fonctionne la réplication maître-esclave ?
La réplication maître – maître (plus généralement — multi – maître ) fonctionne conceptuellement en supposant que les conflits ne sont pas courants et en ne gardant l’ensemble du système que vaguement cohérent, en communiquant de manière asynchrone les mises à jour entre maîtres , ce qui finit par violer les propriétés ACID de base.
Quelles sont les causes du décalage de réplication ?
Qu’est-ce qui cause le lag de réplication ? Le lag de réplication se produit lorsque les esclaves (ou secondaires) ne peuvent pas suivre les mises à jour qui se produisent sur le maître (ou primaire). Les changements non appliqués s’accumulent dans les journaux de relais des esclaves et la version de la base de données sur les esclaves devient de plus en plus différente de celle du maître.
Qu’est-ce que l’architecture mysql maître-esclave ?
Architecture de réplication maître – esclave de MySQL Voici comment fonctionne la réplication MySQL . Les serveurs esclaves obtiennent le journal binaire des maîtres. Les esclaves appliquent ensuite le journal binaire à son journal réel. Le journal de relais est lu par le processus SQL thread et il applique toutes les opérations/données à la base de données du slave et à son journal binaire.
Qu’est-ce que le concept maître-esclave ?
Dans les réseaux informatiques, maître / esclave est un modèle de protocole de communication dans lequel un dispositif ou un processus (appelé maître ) contrôle un ou plusieurs autres dispositifs ou processus (appelés esclaves). Une fois que la relation maître / esclave est établie, la direction du contrôle est toujours du maître vers le ou les esclaves .
Comment configurer la réplication ?
Les étapes suivantes vous guident dans le processus de création du distributeur de réplication SQL :
- Ouvrez SSMS et connectez-vous à l’instance de SQL Server.
- Dans l’Explorateur d’objets, naviguez jusqu’au dossier de réplication, cliquez avec le bouton droit de la souris sur le dossier de réplication, puis cliquez sur Configurer la distribution.
Qu’est-ce qu’une base de données esclave ?
Les bases de données esclaves obtiennent des copies de ces données à partir des maîtres. Les esclaves sont donc en lecture seule du point de vue de l’application alors que les maîtres sont en lecture-écriture. Les écritures dans une base de données sont plus « coûteuses » que les lectures. La vérification de l’intégrité des données et l’écriture des mises à jour sur les disques physiques, par exemple, consomment des ressources système.
Qu’est-ce que la réplication maître MySQL ?
La réplication maître maître MySQL , également connue sous le nom de » mysql réplication enchaînée », « réplication multi maître ou » mysql daisy chaining replication » est une extension de la réplication mysql permettant la création de plusieurs serveurs maître qui peuvent ensuite être maîtres de plusieurs esclaves.
Comment puis-je savoir si l’esclave MySQL fonctionne ?
Vérifier l’état de la réplication MySQL sur les serveurs de requêtes
- .
Démarrez l’utilitaire de ligne de commande MySQL sur le serveur esclave : # cd /opt/mysql/mysql/bin. # mysql -u root -p. Entrez le mot de passe :
- Vérifiez l’état de réplication à l’aide de la commande show slave status (l’état du serveur esclave est véhiculé par les valeurs des colonnes Slave_IO_Running et Slave_SQL_Running) : mysql> ; SHOW SLAVE STATUS G ;
Quel modèle de réplication possède le plus fort pouvoir de résilience ?
Maître-esclave Le modèle de réplication a le plus fort pouvoir de résilience : Avec la distribution maître-esclave, vous réplique les données sur plusieurs noeuds. Un nœud désigne le maître, l’autre l’esclave. Ce maître pourrait être la source faisant autorité pour les données et responsable du traitement de toute mise à jour de ces données.
Combien de types de réplication existe-t-il dans MySQL ?
Il existe deux types fondamentaux de format de réplication , Statement Based Replication (SBR), qui réplique des instructions SQL entières, et Row Based Replication (RBR), qui réplique uniquement les lignes modifiées. Vous pouvez également utiliser une troisième variété, Mixed Based Replication (MBR).
Ai-je besoin du routeur MySQL ?
Le routeur MySQL fait partie du cluster InnoDB, et est un intergiciel léger qui fournit un routage transparent entre votre application et les serveurs MySQL back-end. MySQL Router 8.0 est fortement recommandé pour une utilisation avec MySQL Server 8.0 et 5.7. Pour des notes détaillant les changements de chaque version, consultez les notes de version de MySQL Router .
Comment fonctionne la réplication Gtid ?
17.1. 3.1 Concepts GTID . Un identifiant global de transaction ( GTID ) est un identifiant unique créé et associé à chaque transaction commise sur le serveur d’origine (maître). Cet identifiant est unique non seulement au serveur sur lequel il a été commis, mais il est unique sur tous les serveurs dans une configuration de réplication donnée.
Qu’est-ce que le journal des relais MySQL ?
Le relay log est un ensemble de fichiers log créés par un esclave pendant la réplication. Il se compose d’un ensemble de fichiers relay log et d’un fichier index contenant la liste de tous les fichiers relay log . Les événements sont lus depuis le log binaire du maître et écrits dans le relay log de l’esclave. Ils sont ensuite exécutés sur l’esclave.
Qu’est-ce que la réplication en base de données ?
La réplication de base de données est la copie électronique fréquente de données d’une base de données dans un ordinateur ou un serveur vers une base de données dans un autre — afin que tous les utilisateurs partagent le même niveau d’information.
Comment puis-je surveiller la réplication MySQL ?
Pour surveiller continuellement la réplication , vous pouvez configurer une tâche cron qui exécute le SHOW GLOBAL STATUS comme ‘slave_running’ et SHOW SLAVE STATUS périodiquement et le stocker dans un fichier et même le configurer pour envoyer une alerte par courriel si la valeur de slave_running est ‘NO’.
Qu’est-ce que la réplication de groupe MySQL ?
La réplication de groupe MySQL est un plugin MySQL Server qui vous permet de créer des topologies de réplication élastiques, hautement disponibles et tolérantes aux pannes. Il existe un service d’adhésion au groupe intégré qui maintient la vue du groupe cohérente et disponible pour tous les serveurs à un moment donné.
Qu’est-ce que Binlog ?
Les Binlogs , ou fichiers binary log , sont des journaux de toutes les requêtes MySQL INSERT , UPDATE , et DELETE exécutées contre la base de données active de votre abonnement.
Qu’est-ce que la réplication semi-synchrone ?
« Fondamentalement, ce que fait la réplication semi – synchrone est de s’assurer qu’une transaction/événement a été écrite dans le journal de relais d’au moins un esclave et vidée sur le disque avant de faire le commit sur le nœud maître. »