Que sont les prédicteurs dans la régression ?
En statistique, la régression est une technique utilisée pour prédire les valeurs futures d’une variable dépendante, en utilisant une ou plusieurs variables indépendantes. La variable dépendante est généralement désignée par y et les variables indépendantes par x1, x2, etc.
Un prédicteur en régression est une variable indépendante utilisée pour prédire la valeur de la variable dépendante. En d’autres termes, c’est une variable qui aide à expliquer la variation de la variable dépendante.
Il existe de nombreux types de variables prédictives qui peuvent être utilisées dans l’analyse de régression. Voici quelques exemples courants :
- Variables démographiques telles que l’âge, le sexe, la race et le niveau d’éducation
- Variables économiques telles que le revenu, le type d’emploi et le coût de la vie
- Variables psychologiques telles que le type de personnalité et le niveau d’intelligence
Le choix des variables prédictives dépendra de la question spécifique posée dans la recherche. Par exemple, si nous voulions prédire le succès d’une personne dans sa carrière, nous pourrions choisir d’utiliser des variables démographiques telles que le niveau d’éducation et le type d’emploi comme prédicteurs. Si nous voulions prédire les résultats en matière de santé mentale, nous pourrions choisir d’utiliser des variables psychologiques telles que le niveau d’intelligence et le type de personnalité.
En général, il n’y a pas de règles strictes pour choisir les variables prédictives. Cependant, certaines directives peuvent être utiles :
- Choisissez des variables prédictives pertinentes pour la question posée. Par exemple, si vous souhaitez prédire la réussite professionnelle, choisir des variables prédictives qui mesurent des éléments tels que l’intelligence et l’éthique de travail sera probablement plus utile que de choisir des variables prédictives qui mesurent des éléments tels que la couleur ou la taille des cheveux.
- Choisissez des variables prédictives qui, selon vous, auront une forte relation avec la variable dépendante. Par exemple, si vous souhaitez prédire les résultats en matière de santé mentale, le choix d’une variable prédictive comme le niveau d’intelligence sera probablement plus utile que le choix d’une variable prédictive comme la couleur préférée, car l’intelligence est directement liée à la santé mentale, contrairement à la couleur préférée.
- Évitez de choisir trop de variables prédictives. L’ajout d’un trop grand nombre de variables prédictives peut entraîner des problèmes tels que le « surajustement » où votre modèle devient trop spécifique à l’ensemble de données sur lequel il a été formé et a des difficultés à généraliser à de nouveaux ensembles de données.
La variable de résultat est également appelée la réponse ou variable dépendante, et les facteurs de risque et les facteurs de confusion sont appelés les prédicteurs, ou variables explicatives ou indépendantes. Dans l’analyse de régression, la variable dépendante est désignée par » Y » et les variables indépendantes sont désignées par » X « .
Que sont les prédicteurs dans la régression multiple ?
L’analyse de régression multiple est une technique puissante utilisée pour prédire la valeur inconnue d’une variable à partir de la valeur connue de deux variables ou plus – également appelées les prédicteurs.
Combien de prédicteurs y a-t-il dans une régression ?
En statistique, la règle du un sur dix est une règle empirique pour savoir combien de paramètres prédicteurs peuvent être estimés à partir des données lors d’une analyse de régression (en particulier les modèles à risques proportionnels dans l’analyse de survie et la régression logistique) tout en gardant le risque de surajustement faible.
Que sont les prédicteurs en statistiques ?
La variable prédicteur fournit des informations sur une variable dépendante associée concernant un résultat particulier. Au niveau le plus fondamental, les variables prédicteurs sont des variables qui sont liées à des résultats particuliers. En tant que telles, les variables prédicteurs sont des extensions des statistiques corrélationnelles.
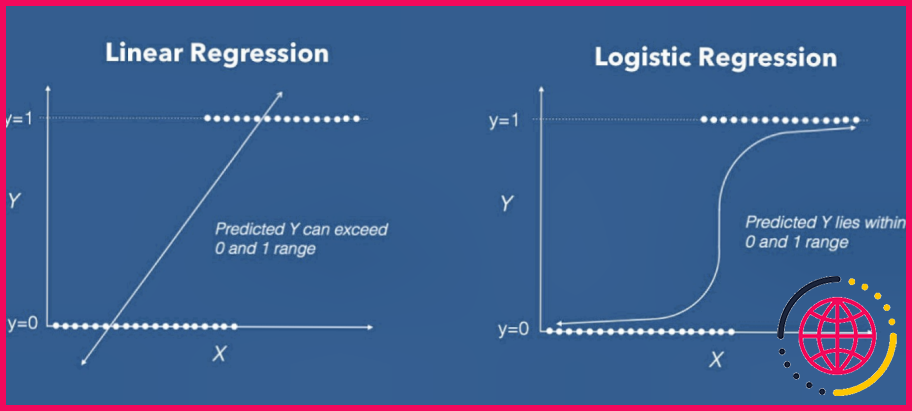
Qu’est-ce qu’une variable prédictive dans une régression linéaire ?
Dans une régression linéaire simple, nous prédisons les scores d’une variable à partir des scores d’une deuxième variable. La variable que nous prédisons est appelée la variable critère et est désignée par Y. La variable sur laquelle nous basons nos prédictions est appelée la variable prédicteur et est désignée par X.
Quel est un exemple de régression ?
La régression est un retour à des stades de développement antérieurs et à des formes abandonnées de gratification qui leur appartiennent, poussé par des dangers ou des conflits survenant à l’un des stades ultérieurs. Une jeune épouse, par exemple, peut se retirer dans la sécurité de la maison de ses parents après son.
Quelles sont les quatre hypothèses de la régression linéaire ?
- Hypothèse 1 : relation linéaire.
- Hypothèse 2 : Indépendance.
- Hypothèse 3 : Homoscédasticité.
- Hypothèse 4 : Normalité.
Comment trouver les prédicteurs ?
Généralement la variable avec la corrélation la plus élevée est un bon prédicteur. Vous pouvez également comparer les coefficients pour sélectionner le meilleur prédicteur (Assurez-vous d’avoir normalisé les données avant d’effectuer la régression et vous prenez la valeur absolue des coefficients). Vous pouvez également regarder l’évolution de la valeur de R-carré.
Quel est l’exemple d’une covariable ?
Par exemple, vous faites une expérience pour voir comment les plants de maïs tolèrent la sécheresse. Le niveau de sécheresse est le « traitement » réel, mais ce n’est pas le seul facteur qui affecte la façon dont les plantes se comportent : la taille est un facteur connu qui affecte les niveaux de tolérance, donc vous feriez fonctionner la taille de la plante comme une covariable.
Quels sont les 3 types de variables ?
Il y a trois variables principales : la variable indépendante, la variable dépendante et les variables contrôlées. Exemple : une voiture qui descend sur différentes surfaces.
Comment éviter l’overfitting dans la régression ?
La meilleure solution à un problème d’overfitting est l’évitement. Identifiez les variables importantes et réfléchissez au modèle que vous êtes susceptible de spécifier, puis planifiez à l’avance la collecte d’un échantillon suffisamment grand pour gérer tous les prédicteurs, interactions et termes polynomiaux que votre variable de réponse pourrait nécessiter.
Comment tester l’overfitting de la régression ?
Comment détecter les modèles surajustés
- Il supprime un point de données de l’ensemble de données.
- Calcule l’équation de régression.
- Évalue la capacité du modèle à prédire l’observation manquante.
- Et, répète ceci pour tous les points de données dans l’ensemble de données.
Quelle est une bonne valeur prédite de R au carré ?
Toute étude qui tente de prédire le comportement humain aura tendance à avoir des valeurs R au carré inférieures à 50%. Cependant, si vous analysez un processus physique et que vous disposez de très bonnes mesures, vous pouvez vous attendre à des valeurs de R au carré supérieures à 90%.
Comment expliquez-vous la régression par paliers ?
La régression par étapes est la construction itérative, étape par étape, d’un modèle de régression qui implique la sélection de variables indépendantes à utiliser dans un modèle final. Elle consiste à ajouter ou à supprimer successivement des variables explicatives potentielles et à tester la signification statistique après chaque itération.
Quels sont les trois types de régression multiple ?
Il existe plusieurs types d’analyses de régression multiple (par exemple, standard, hiérarchique, setwise, stepwise) dont seulement deux seront présentés ici (standard et stepwise). Le type d’analyse effectué dépend de la question qui intéresse le chercheur.
Comment interpréter les résultats d’une régression ?
Le signe d’un coefficient de régression vous indique s’il existe une corrélation positive ou négative entre chaque variable indépendante et la variable dépendante. Un coefficient positif indique que lorsque la valeur de la variable indépendante augmente, la moyenne de la variable dépendante tend également à augmenter.
L’âge est-il une covariable ?
Vous pouvez ajouter l’âge comme covariable continue, mais gardez à l’esprit que, par exemple, ~âge + . implique que l’expression génétique aura des augmentations multiplicatives avec chaque unité d’âge.
Le temps peut-il être une covariable ?
La covariance variant dans le temps se produit lorsqu’une covariable change dans le temps pendant la période de suivi. Une telle variable peut être analysée avec le modèle de régression de Cox pour estimer son effet sur le temps de survie.
Que sont les prédicteurs en psychologie ?
Nom. Variante ou autre donnée utilisée pour approcher ou prédire les performances, le bien-être ou tout autre état futurs.
Comment savoir si un prédicteur est significatif ?
Une faible valeur p (< 0,05) indique que vous pouvez rejeter l’hypothèse nulle. En d’autres termes, un prédicteur qui a une faible valeur p est susceptible d’être un ajout significatif à votre modèle parce que les changements dans la valeur du prédicteur sont liés aux changements dans la variable de réponse.
Comment sélectionner les prédicteurs pour une régression linéaire ?
Lorsque vous construisez un modèle de régression linéaire ou logistique, vous devez envisager d’inclure :
- Des variables dont il est déjà prouvé dans la littérature qu’elles sont liées au résultat.
- Des variables qui peuvent être considérées soit comme la cause de l’exposition, soit comme le résultat, soit comme les deux.
- Les termes d’interaction des variables qui ont des effets principaux importants.
Quelles sont les 5 principales hypothèses importantes de la régression ?
La régression a cinq hypothèses clés :
- Une relation linéaire.
- Normalité multivariée.
- Pas ou peu de multicollinéarité.
- Pas d’auto-corrélation.
- Homoscédasticité.
Les données doivent-elles être normales pour la régression ?
Vous n’avez pas besoin de supposer des distributions normales pour faire de la régression. La régression par les moindres carrés est l’estimateur BLUE (Best Linear, Unbiased Estimator) quelles que soient les distributions.
Quelles sont les hypothèses les plus importantes dans la régression linéaire ?
Il y a quatre hypothèses associées à un modèle de régression linéaire : La linéarité : La relation entre X et la moyenne de Y est linéaire. Homoscédasticité : La variance du résidu est la même pour toute valeur de X. Indépendance : Les observations sont indépendantes les unes des autres.