Qu’est-ce que le clustering dans l’apprentissage non supervisé ?
» Clustering » est le processus de regroupement d’entités similaires. L’objectif de cette technique d’apprentissage automatique non supervisé est de trouver des similitudes dans le point de données et de regrouper les points de données similaires. Pourquoi utiliser le Clustering ? Le regroupement d’entités similaires aide à profiler les attributs des différents groupes.
Alors, le clustering est-il un apprentissage non supervisé ou supervisé ?
Le clustering K-means est un algorithme d’apprentissage non supervisé . Dans ce cas, vous n’avez pas de données étiquetées contrairement à l’apprentissage supervisé . C’est en cela que consiste le clustering k-means. Le terme K est essentiellement est un nombre et vous devez indiquer au système combien de clusters vous devez effectuer.
Aussi, quels sont les types d’apprentissage non supervisé ?
L’apprentissage machine supervisé vous aide à trouver tous les genres de modèles inconnus dans les données. Clustering et Association sont deux types d’apprentissage non supervisé . Quatre types de méthodes de clustering sont 1) exclusives 2) agglomératives 3) superposées 4) probabilistes.
En outre, qu’entend-on par apprentissage non supervisé ?
L’apprentissage non supervisé est la formation d’un algorithme d’intelligence artificielle (IA) utilisant des informations qui ne sont ni classées ni étiquetées et permettant à l’algorithme d’agir sur ces informations sans guide. Les algorithmes d’apprentissage non supervisé peuvent effectuer des tâches de traitement plus complexes que les systèmes d’ apprentissage supervisé.
Comment l’apprentissage non supervisé est-il lié au problème de regroupement statistique ?
Le regroupement peut être considéré comme le plus important problème d’ apprentissage non supervisé ; ainsi, comme tout autre problème de ce type, il s’agit de trouver une structure dans une collection de données non étiquetées. Une définition libre du clustering pourrait être « le processus d’organisation des objets en groupes dont les membres sont similaires d’une certaine manière ».
Qu’est-ce que l’apprentissage non supervisé exemple ?
Il peut y avoir des exemples d’apprentissage automatique non supervisé tels que le k-means Clustering , le modèle de Markov caché, le DBSCAN Clustering , le PCA, le t-SNE, le SVD, la règle d’association. Voyons-en quelques-uns : k-means Clustering – Data Mining. k-means clustering est l’algorithme central dans l’opération d’apprentissage automatique non supervisé .
Quelle est la meilleure méthode de clustering ?
Nous examinerons 5 algorithmes de clustering populaires que tout data scientist devrait connaître.
- Algorithme de clustering K-means.
- Algorithme de clustering à décalage moyen.
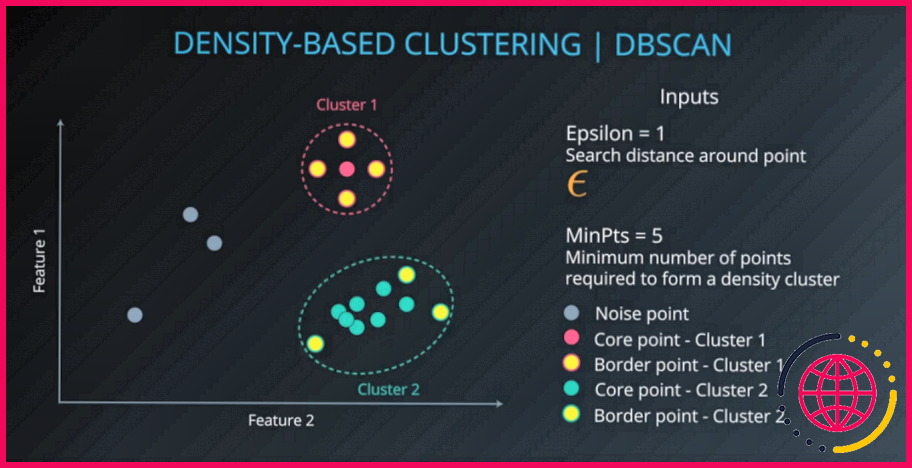
- DBSCAN – Clustering spatial basé sur la densité des applications avec bruit.
- EM utilisant GMM – Clustering par espérance-maximisation (EM) utilisant des modèles de mélange gaussien (GMM)
Que sont les techniques de clustering ?
Les méthodes de clustering sont utilisées pour identifier des groupes d’objets similaires dans un ensemble de données multivariées collectées dans des domaines tels que le marketing, le bio-médical et le géo-spatial. Il existe différents types de méthodes de clustering , notamment : Les méthodes de partitionnement . Le clustering hiérarchique. Le clustering flou.
Pourquoi le clustering est-il appelé apprentissage non supervisé ?
Le clustering est une tâche d’ apprentissage machine non supervisé qui divise automatiquement les données en clusters , ou groupes d’éléments similaires. Le clustering est guidé par le principe selon lequel les éléments à l’intérieur d’un cluster doivent être très similaires les uns aux autres, mais très différents de ceux qui se trouvent à l’extérieur.
Le clustering est-il un apprentissage supervisé ?
Le clustering est une approche d’ apprentissage machine non supervisé, mais peut-il être utilisé pour améliorer la précision des algorithmes d’ apprentissage machine supervisé également en classant les points de données dans des groupes similaires et en utilisant ces étiquettes de cluster comme variables indépendantes dans l’algorithme d’ apprentissage machine supervisé ?
À quoi servent les algorithmes de clustering ?
Le clustering est une méthode d’apprentissage non supervisé et une technique courante d’analyse statistique des données utilisée dans de nombreux domaines. En science des données, nous pouvons utiliser l’analyse du clustering pour obtenir des informations précieuses sur nos données en voyant dans quels groupes les points de données se rangent lorsque nous appliquons un algorithme de clustering .
Pourquoi le clustering est-il fait ?
Clustering
est importante dans les applications d’analyse de données et de data mining. C’est la tâche de regrouper un ensemble d’objets de sorte que les objets d’un même groupe soient plus similaires les uns aux autres que ceux d’autres groupes ( clusters ).
La régression est-elle supervisée ou non supervisée ?
La régression linéaire est supervisée . C’est plus un classificateur qu’une technique de régression , malgré son nom. Vous essayez de prédire le rapport des probabilités d’appartenance à une classe, comme les probabilités de décès d’une personne. Des exemples d’apprentissage non supervisé incluent le regroupement et l’analyse d’association.
Quelles sont les fonctions de l’apprentissage non supervisé ?
L’apprentissage non supervisé est un type d’algorithme d’apprentissage automatique utilisé pour tirer des inférences à partir d’ensembles de données constitués de données d’entrée sans réponses étiquetées. La méthode d’apprentissage non supervisé la plus courante est l’analyse en grappes, qui est utilisée pour l’analyse exploratoire des données afin de trouver des modèles cachés ou des regroupements dans les données.
Comment fonctionne l’apprentissage non supervisé ?
Dans l’apprentissage non supervisé , un système d’IA est présenté avec des données non étiquetées, non catégorisées et les algorithmes du système agissent sur les données sans formation préalable. En substance, l’ apprentissage non supervisé peut être considéré comme un apprentissage sans professeur. Dans le cas de l’ apprentissage supervisé , le système dispose à la fois des entrées et des sorties.
Quel est l’objectif de l’apprentissage non supervisé ?
L’apprentissage automatique non supervisé . L’apprentissage non supervisé est celui où vous n’avez que des données d’entrée (X) et aucune variable de sortie correspondante. Le but de l’apprentissage non supervisé est de modéliser la structure ou la distribution sous-jacente dans les données afin de apprendre davantage sur les données.
La CNN est-elle supervisée ou non supervisée ?
Soit pour prédire (régression) quelque chose, soit dans la classification. La classification d’images basée sur leurs attributs est l’une des applications les plus célèbres du CNN . La réponse à votre question est – A la fois supervisée et non supervisée (cela dépend de l’exigence). Cependant, principalement supervisé .
Quelle est la différence entre l’apprentissage supervisé et l’apprentissage non supervisé ?
L’apprentissage supervisé est la technique qui consiste à accomplir une tâche en fournissant une formation , des modèles d’entrée et de sortie aux systèmes alors que l’ apprentissage non supervisé est une technique d’auto- apprentissage dans laquelle le système doit découvrir les caractéristiques de la population d’entrée par lui-même et aucun ensemble préalable de catégories n’est utilisé.
Qu’est-ce qu’une donnée non supervisée ?
La science des données non supervisées ou données non dirigées découvre des modèles cachés dans des données non étiquetées. Dans la science des données non supervisées , il n’y a pas de variables de sortie à prédire. L’objectif de cette classe de techniques de science des données , est de trouver des modèles dans les données sur la base de la relation entre les données points eux-mêmes.
L’apprentissage CNN est-il non supervisé ?
Les réseaux, CNN et RNN, sont-ils basés sur un apprentissage supervisé ou un apprentissage non supervisé ? Ni l’un ni l’autre. Actuellement, la méthode de loin la plus populaire est l’ apprentissage supervisé , mais l’ non supervisé et l’ apprentissage auto — supervisé sont définitivement possibles, et gagnent en traction dans certains cas d’utilisation (par exemple, l’autoencodeur ).
Qu’est-ce que l’apprentissage supervisé et non supervisé expliquer avec les exemples ?
L’apprentissage machine supervisé vous aide à trouver toutes sortes de modèles inconnus dans les données. Pour exemple , Bébé peut identifier d’autres chiens en fonction de l’ apprentissage non supervisé passé. La régression et la Classification sont deux types de techniques d’ apprentissage machine supervisé. Clustering et Association sont deux types d’apprentissage non supervisé .
Qu’est-ce que la classification supervisée et non supervisée ?
Deux grandes catégories de techniques de classification d’images comprennent la non supervisée (calculée par un logiciel) et la supervisée (guidée par l’homme) classification . L’utilisateur peut spécifier l’algorithme que le logiciel utilisera et le nombre souhaité de classes de sortie, mais il n’aide pas autrement au processus de classification .
Algorithme de clustering K-means. Algorithme de clustering à décalage moyen. DBSCAN - Clustering spatial basé sur la densité des applications avec bruit. EM utilisant GMM - Clustering par espérance-maximisation (EM) utilisant des modèles de mélange gaussien (GMM) " } }, {"@type": "Question","name": " Que sont les techniques de clustering ? ","acceptedAnswer": {"@type": "Answer","text": " Les méthodes de clustering sont utilisées pour identifier des groupes d'objets similaires dans un ensemble de données multivariées collectées dans des domaines tels que le marketing, le bio-médical et le géo-spatial. Il existe différents types de méthodes de clustering, notamment : Les méthodes de partitionnement. Le clustering hiérarchique. Le clustering flou." } }, {"@type": "Question","name": " Pourquoi le clustering est-il appelé apprentissage non supervisé ? ","acceptedAnswer": {"@type": "Answer","text": " Le clustering est une tâche d'apprentissage machine non supervisé qui divise automatiquement les données en clusters, ou groupes d'éléments similaires. Le clustering est guidé par le principe selon lequel les éléments à l'intérieur d'un cluster doivent être très similaires les uns aux autres, mais très différents de ceux qui se trouvent à l'extérieur." } }, {"@type": "Question","name": " Le clustering est-il un apprentissage supervisé ? ","acceptedAnswer": {"@type": "Answer","text": " Le clustering est une approche d'apprentissage machine non supervisé, mais peut-il être utilisé pour améliorer la précision des algorithmes d'apprentissage machine supervisé également en classant les points de données dans des groupes similaires et en utilisant ces étiquettes de cluster comme variables indépendantes dans l'algorithme d'apprentissage machine supervisé ?" } }, {"@type": "Question","name": " À quoi servent les algorithmes de clustering ? ","acceptedAnswer": {"@type": "Answer","text": " Le clustering est une méthode d'apprentissage non supervisé et une technique courante d'analyse statistique des données utilisée dans de nombreux domaines. En science des données, nous pouvons utiliser l'analyse du clustering pour obtenir des informations précieuses sur nos données en voyant dans quels groupes les points de données se rangent lorsque nous appliquons un algorithme de clustering." } }, {"@type": "Question","name": " La régression est-elle supervisée ou non supervisée ? ","acceptedAnswer": {"@type": "Answer","text": " La régression linéaire est supervisée. C'est plus un classificateur qu'une technique de régression, malgré son nom. Vous essayez de prédire le rapport des probabilités d'appartenance à une classe, comme les probabilités de décès d'une personne. Des exemples d'apprentissage non supervisé incluent le regroupement et l'analyse d'association.
" } }, {"@type": "Question","name": " Quelles sont les fonctions de l'apprentissage non supervisé ? ","acceptedAnswer": {"@type": "Answer","text": " L'apprentissage non supervisé est un type d'algorithme d'apprentissage automatique utilisé pour tirer des inférences à partir d'ensembles de données constitués de données d'entrée sans réponses étiquetées. La méthode d'apprentissage non supervisé la plus courante est l'analyse en grappes, qui est utilisée pour l'analyse exploratoire des données afin de trouver des modèles cachés ou des regroupements dans les données." } }, {"@type": "Question","name": " Comment fonctionne l'apprentissage non supervisé ? ","acceptedAnswer": {"@type": "Answer","text": " Dans l'apprentissage non supervisé, un système d'IA est présenté avec des données non étiquetées, non catégorisées et les algorithmes du système agissent sur les données sans formation préalable. En substance, l'apprentissage non supervisé peut être considéré comme un apprentissage sans professeur. Dans le cas de l'apprentissage supervisé, le système dispose à la fois des entrées et des sorties." } }, {"@type": "Question","name": " Quel est l'objectif de l'apprentissage non supervisé ? ","acceptedAnswer": {"@type": "Answer","text": " L'apprentissage automatique non supervisé. L'apprentissage non supervisé est celui où vous n'avez que des données d'entrée (X) et aucune variable de sortie correspondante. Le but de l'apprentissage non supervisé est de modéliser la structure ou la distribution sous-jacente dans les données afin de apprendre davantage sur les données." } }, {"@type": "Question","name": " La CNN est-elle supervisée ou non supervisée ? ","acceptedAnswer": {"@type": "Answer","text": " Soit pour prédire (régression) quelque chose, soit dans la classification. La classification d'images basée sur leurs attributs est l'une des applications les plus célèbres du CNN. La réponse à votre question est - A la fois supervisée et non supervisée (cela dépend de l'exigence). Cependant, principalement supervisé." } }, {"@type": "Question","name": " Quelle est la différence entre l'apprentissage supervisé et l'apprentissage non supervisé ? ","acceptedAnswer": {"@type": "Answer","text": " L'apprentissage supervisé est la technique qui consiste à accomplir une tâche en fournissant une formation, des modèles d'entrée et de sortie aux systèmes alors que l'apprentissage non supervisé est une technique d'auto-apprentissage dans laquelle le système doit découvrir les caractéristiques de la population d'entrée par lui-même et aucun ensemble préalable de catégories n'est utilisé." } }, {"@type": "Question","name": " Qu'est-ce qu'une donnée non supervisée ? ","acceptedAnswer": {"@type": "Answer","text": " La science des données non supervisées ou données non dirigées découvre des modèles cachés dans des données non étiquetées. Dans la science des données non supervisées, il n'y a pas de variables de sortie à prédire. L'objectif de cette classe de techniques de science des données, est de trouver des modèles dans les données sur la base de la relation entre les données points eux-mêmes." } }, {"@type": "Question","name": " L'apprentissage CNN est-il non supervisé ? ","acceptedAnswer": {"@type": "Answer","text": " Les réseaux, CNN et RNN, sont-ils basés sur un apprentissage supervisé ou un apprentissage non supervisé ? Ni l'un ni l'autre. Actuellement, la méthode de loin la plus populaire est l'apprentissage supervisé, mais l'non supervisé et l'apprentissage auto -- supervisé sont définitivement possibles, et gagnent en traction dans certains cas d'utilisation (par exemple, l'autoencodeur )." } }, {"@type": "Question","name": " Qu'est-ce que l'apprentissage supervisé et non supervisé expliquer avec les exemples ? ","acceptedAnswer": {"@type": "Answer","text": " L'apprentissage machine supervisé vous aide à trouver toutes sortes de modèles inconnus dans les données. Pour exemple, Bébé peut identifier d'autres chiens en fonction de l'apprentissage non supervisé passé. La régression et la Classification sont deux types de techniques d'apprentissage machine supervisé. Clustering et Association sont deux types d'apprentissage non supervisé." } }] }