Comment utiliser Scikit-LLM pour l’analyse de texte avec de grands modèles de langage

Scikit-LLM est un paquetage Python qui permet d’intégrer de grands modèles de langage (LLM) dans le cadre de scikit-learn. Il permet d’accomplir des tâches d’analyse de texte. Si vous êtes familier avec scikit-learn, il vous sera plus facile de travailler avec Scikit-LLM.
Il est important de noter que Scikit-LLM ne remplace pas scikit-learn. scikit-learn est une bibliothèque d’apprentissage automatique à usage général, mais Scikit-LLM est spécifiquement conçu pour les tâches d’analyse de texte.
Démarrer avec Scikit-LLM
Pour démarrer avec Scikit-LLM vous devez installer la bibliothèque et configurer votre clé API. Pour installer la bibliothèque, ouvrez votre IDE et créez un nouvel environnement virtuel. Cela permettra d’éviter tout conflit de version de la bibliothèque. Ensuite, exécutez la commande suivante dans le terminal.
Cette commande installera Scikit-LLM et ses dépendances requises.
Pour configurer votre clé API, vous devez en obtenir une auprès de votre fournisseur LLM. Pour obtenir la clé API OpenAI, suivez les étapes suivantes :
Passez à la page OpenAI API. Cliquez ensuite sur votre profil situé dans le coin supérieur droit de la fenêtre. Sélectionnez Voir les clés API. Vous accéderez ainsi à la page clés API de l’API.
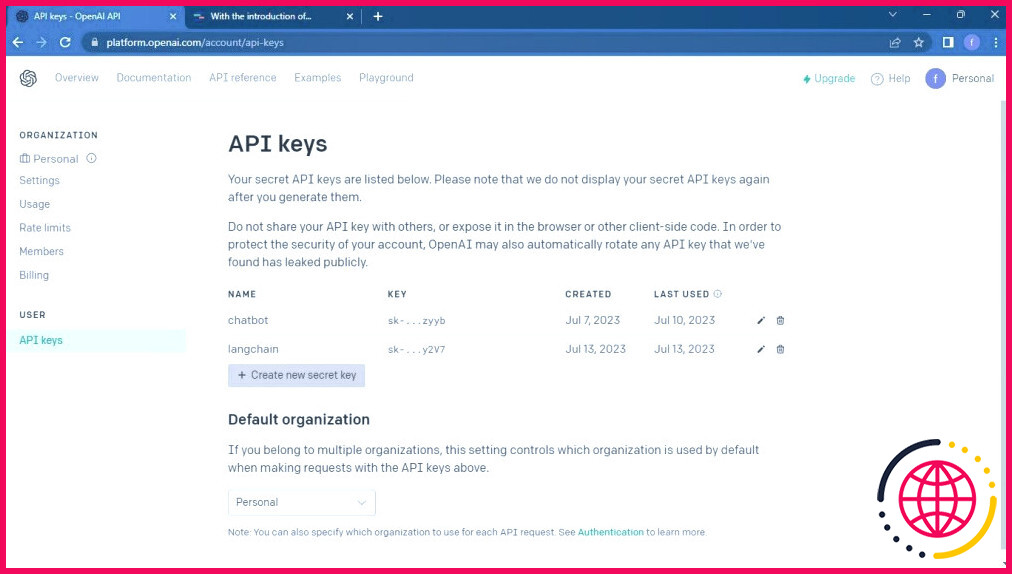
Sur la page clés API cliquez sur l’icône Créer une nouvelle clé secrète pour créer une nouvelle clé secrète.
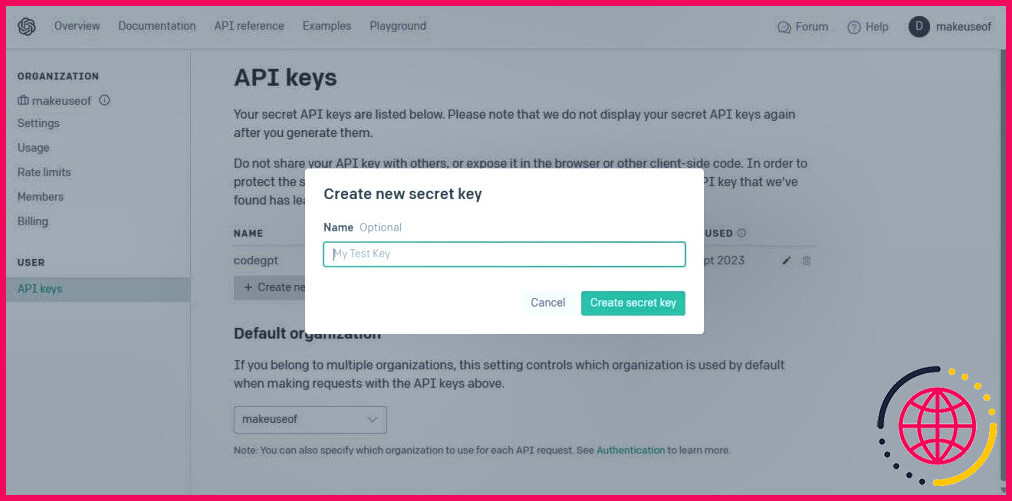
Nommez votre clé API et cliquez sur le bouton Créer une clé secrète pour générer la clé. Après la génération, vous devez copier la clé et la conserver dans un endroit sûr, car OpenAI n’affichera plus la clé. Si vous la perdez, vous devrez en générer une nouvelle.
Le code source complet est disponible dans un dépôt GitHub.
Maintenant que vous avez votre clé API, ouvrez votre IDE et importez SKLLMConfig de la bibliothèque Scikit-LLM. Cette classe vous permet de définir des options de configuration liées à l’utilisation de grands modèles de langage.
Cette classe attend de vous que vous définissiez votre clé API OpenAI et les détails de votre organisation.
L’identifiant de l’organisation et le nom ne sont pas les mêmes. L’identifiant de l’organisation est un identifiant unique de votre organisation. Pour obtenir l’identifiant de votre organisation, passez à l’étape Organisation de l’OpenAI et copiez-le. Vous avez maintenant établi une connexion entre Scikit-LLM et le grand modèle de langage.
Scikit-LLM exige que vous ayez un plan de paiement à l’utilisation. En effet, le compte d’essai gratuit d’OpenAI est limité à trois requêtes par minute, ce qui n’est pas suffisant pour Scikit-LLM.
Si vous essayez d’utiliser le compte d’essai gratuit, vous obtiendrez une erreur similaire à celle ci-dessous lors de l’analyse de texte.

Pour en savoir plus sur les limites de taux. Passez à la page OpenAI rate limits page.
Le fournisseur de LLM n’est pas limité à OpenAI. Vous pouvez également utiliser d’autres fournisseurs LLM.
Importation des bibliothèques requises et chargement de l’ensemble de données
Importez pandas que vous utiliserez pour charger le jeu de données. Importez également les classes requises dans Scikit-LLM et scikit-learn.
Ensuite, chargez l’ensemble de données sur lequel vous souhaitez effectuer une analyse de texte. Ce code utilise l’ensemble de données de films IMDB. Vous pouvez toutefois le modifier pour utiliser votre propre jeu de données.
Il n’est pas obligatoire d’utiliser uniquement les 100 premières lignes de l’ensemble de données. Vous pouvez utiliser l’ensemble de vos données.
Ensuite, extrayez les caractéristiques et les colonnes d’étiquetage. Divisez ensuite votre ensemble de données en ensembles de formation et de test.
Les Le genre contient les étiquettes que vous souhaitez prédire.
Classification de texte à partir de zéro avec Scikit-LLM
La classification de texte à partir de zéro est une fonctionnalité offerte par les grands modèles de langage. Elle permet de classer le texte dans des catégories prédéfinies sans avoir besoin d’une formation explicite sur des données étiquetées. Cette capacité est très utile lorsque vous devez classer du texte dans des catégories que vous n’aviez pas prévues lors de l’apprentissage du modèle.
Pour effectuer une classification de texte à partir de zéro à l’aide de Scikit-LLM, utilisez l’option ZeroShotGPTClassifier classe.
La sortie est la suivante :
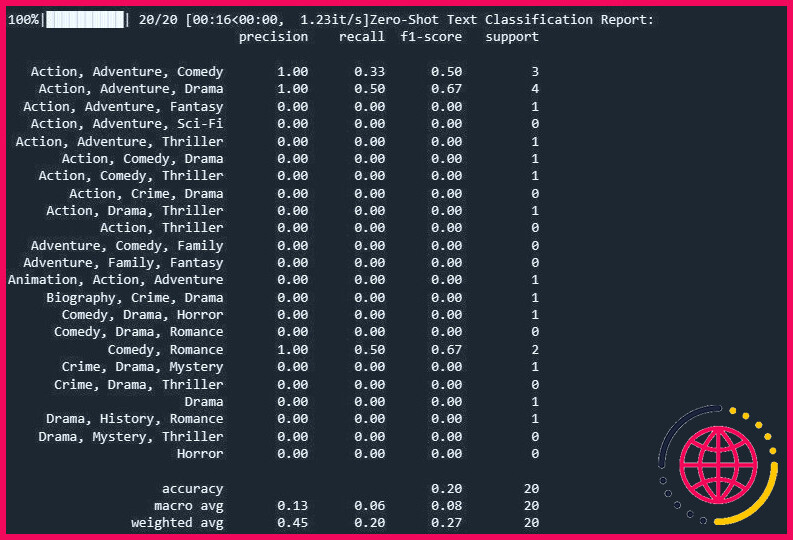
Le rapport de classification fournit des mesures pour chaque étiquette que le modèle tente de prédire.
Classification de texte multi-label Zero-Shot avec Scikit-LLM
Dans certains scénarios, un texte unique peut appartenir simultanément à plusieurs catégories. Les modèles de classification traditionnels ont du mal à gérer cette situation. Scikit-LLM, en revanche, rend cette classification possible. La classification multi-label de textes à partir de zéro est cruciale pour attribuer plusieurs étiquettes descriptives à un seul échantillon de texte.
Utilisation MultiLabelZeroShotGPTClassifier pour prédire quelles étiquettes sont appropriées pour chaque échantillon de texte.
Dans le code ci-dessus, vous définissez les étiquettes candidates auxquelles votre texte pourrait appartenir.
Le résultat est le suivant :
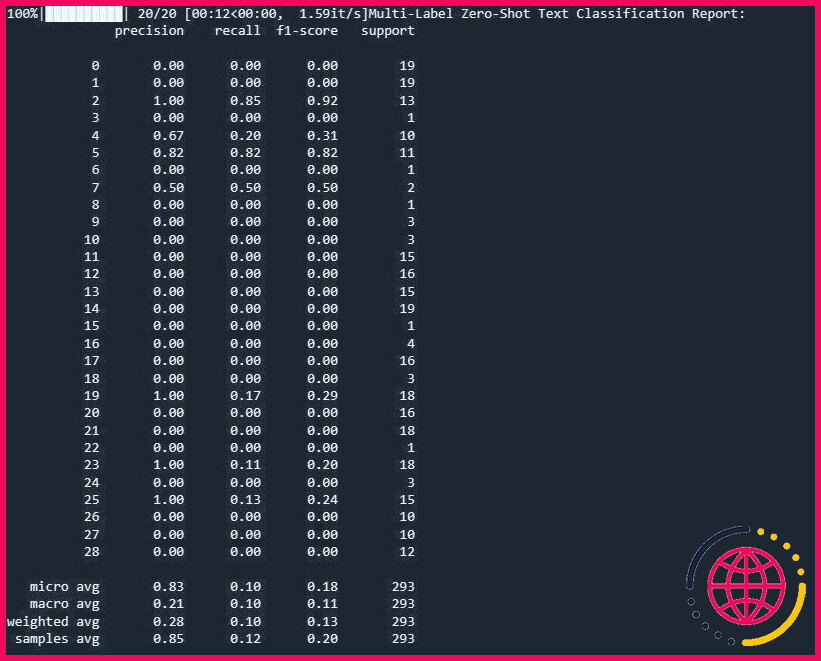
Ce rapport vous aide à comprendre les performances de votre modèle pour chaque étiquette dans le cadre d’une classification multiétiquette.
Vectorisation de texte avec Scikit-LLM
Dans la vectorisation de texte, les données textuelles sont converties dans un format numérique que les modèles d’apprentissage automatique peuvent comprendre. Scikit-LLM propose pour cela le GPTVectorizer. Il vous permet de transformer le texte en vecteurs à dimension fixe à l’aide de modèles GPT.
Vous pouvez y parvenir en utilisant le Term Frequency-Inverse Document Frequency.
Voici le résultat :
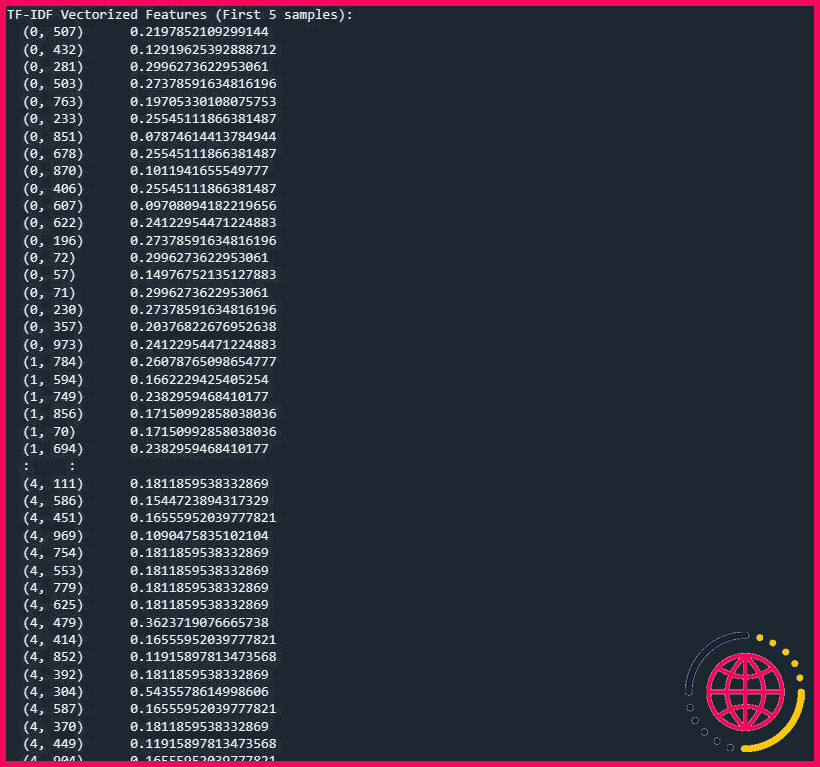
La sortie représente les caractéristiques vectorisées TF-IDF pour les 5 premiers échantillons de l’ensemble de données.
Résumé de texte avec Scikit-LLM
Le résumé de texte permet de condenser un morceau de texte tout en préservant les informations les plus importantes. Scikit-LLM propose le GPTSummarizer, qui utilise les modèles GPT pour générer des résumés de texte concis.
Le résultat est le suivant :
Ce qui précède est un résumé des données de test.
Construire des applications au-dessus des LLM
Scikit-LLM ouvre un monde de possibilités pour l’analyse de texte avec de grands modèles de langage. Il est essentiel de comprendre la technologie qui sous-tend les grands modèles de langage. Cela vous aidera à comprendre leurs forces et leurs faiblesses, ce qui vous permettra de créer des applications efficaces à partir de cette technologie de pointe.





