Qu’est-ce que le format de fichier en bioinformatique ?
Le format de fichier le plus utilisé pour les séquences de référence est le format fasta. Les séquences nucléotidiques et protéiques peuvent toutes deux être représentées en format fasta format . Un fichier au format fasta commence par une description d’une seule ligne, suivie des données de la séquence. La ligne de description commence par un symbole plus grand que (« > ; »).
De même, on se demande quel est un exemple de format Fasta ?
En bio-informatique et en biochimie, le FASTA format est un format textuel pour représenter soit des séquences de nucléotides, soit des séquences d’acides aminés (protéines), dans lequel les nucléotides ou les acides aminés sont représentés à l’aide de codes à une seule lettre.
Identifiants du NCBI.
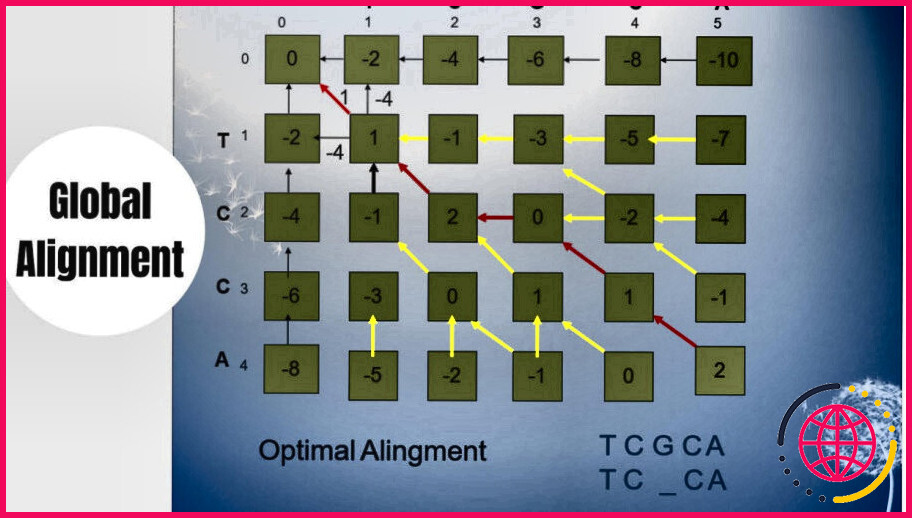
| Type | Format(s) | Exemple(s) |
|---|---|---|
| RefSeq | ref|accession|nom | ref|NM_010450.1| |
De même, qu’est-ce que la bioinformatique et ses applications ?
La bioinformatique est la branche de la science qui utilise les applications des technologies de l’information et de l’informatique dans le domaine de la biologie moléculaire. C’est Paulien Hogeweg qui a inventé le terme Bioinformatique en 1979 pour étudier les processus de la technologie de l’information dans les systèmes biologiques.
Dans ce contexte, qu’est-ce que le format GenBank ?
genbank ) Le format GenBank ( GenBank Flat File Format ) stocke la séquence et son annotation ensemble. Le début de la section de la séquence est marqué par une ligne commençant par le mot « ORIGINE » et la fin de la section est marquée par une ligne avec seulement « // ». Le fichier GenBank se termine généralement par . gb ou parfois .
Quelle est la différence entre Fasta et Fastq ?
FASTA pour stocker le génome/transcriptome de référence auquel les fragments de séquence seront mappés. FASTQ pour stocker les fragments de séquence avant la cartographie.
À quoi sert la GenBank ?
GenBank ® est une base de données complète qui contient des séquences nucléotidiques accessibles au public pour plus de 300 000 organismes nommés au niveau du genre ou à un niveau inférieur, obtenues principalement par des soumissions de laboratoires individuels et des soumissions par lots de projets de séquençage à grande échelle, y compris le shotgun du génome entier (
Qu’est-ce que le format de la séquence ?
Un format de séquence définit la disposition et le contenu autorisés du texte dans un fichier. Cela inclut les tokens de texte qui définissent les champs utilisés dans une banque de données. Ces champs comprennent la séquence elle-même, le nom de l’identifiant de la séquence et le numéro d’accession, entre autres.
Que signifie Fasta ?
FAST-All
Que signifie Fastq ?
Le format Fastq est un format textuel permettant de stocker à la fois une séquence biologique (généralement une séquence de nucléotides) et les scores de qualité correspondants. La lettre de la séquence et le score de qualité sont chacun codés avec un seul caractère ASCII pour des raisons de brièveté.
Comment fonctionne Fasta ?
FASTA est un outil d’alignement de séquences par paires qui prend en entrée des séquences de nucléotides ou de protéines et les compare aux bases de données existantes C’est un format textuel qui peut être lu et écrit à l’aide d’un éditeur de texte ou d’un traitement de texte.
Qu’est-ce que Fasta et Blast ?
BLAST et FASTA sont deux programmes de recherche de similarité qui identifient les séquences d’ADN et les protéines homologues sur la base de l’excès de similarité de séquence. Ils fournissent des facilités pour comparer les séquences d’ADN et de protéines avec les bases de données d’ADN et de protéines existantes.
Comment dois-je formater un fichier Fasta ?
Utiliser le format Plain Text :
- Utiliser un éditeur de texte (par exemple, WordPad) pour préparer le fichier FASTA des séquences de nucléotides.
- S’assurer d’enregistrer votre fichier en tant que Plain Text ou document texte.
- Si vous n’êtes pas sûr que l’option « Enregistrer » de votre programme le fasse automatiquement, utilisez « Enregistrer sous ».
Qu’est-ce que la base de données NCBI ?
Centre national d’information sur la biotechnologie. Le NCBI abrite une série de bases de données pertinentes pour la biotechnologie et la biomédecine et constitue une ressource importante pour les outils et services bioinformatiques. Les principales bases de données comprennent GenBank pour les séquences d’ADN et PubMed, une base de données bibliographique pour la littérature biomédicale.
La GenBank est-elle une base de données primaire ?
Il existe trois dépôts de nucléotides ou bases de données primaires pour la soumission des séquences de nucléotides et de génomes : GenBank
hébergée par le National Center for Biotechnology Information (ou NCBI). L’archive européenne de nucléotides ou ENA hébergée par les laboratoires européens de biologie moléculaire (EMBL).
Comment GenBank est-elle financée ?
Le financement a été fourni par les Instituts nationaux de la santé, la Fondation nationale des sciences, le Département de l’énergie et le Département de la défense. Le LANL a collaboré à GenBank avec la firme Bolt, Beranek, et Newman, et à la fin de 1983, plus de 2 000 séquences y étaient stockées.
À quoi sert UniProt ?
UniProt est une base de données librement accessible de séquences de protéines et d’informations fonctionnelles, de nombreuses entrées étant issues de projets de séquençage du génome. Elle contient une grande quantité d’informations sur la fonction biologique des protéines dérivées de la littérature de recherche.
Qu’est-ce que GenPept ?
Description. La base de données GenPept est une collection de séquences basées sur des traductions de régions codantes annotées dans la GenBank.
Qu’est-ce que le nom du locus ?
En génétique, un locus (pluriel loci ) est une position spécifique et fixe sur un chromosome où se trouve un gène ou un marqueur génétique particulier. La liste ordonnée des loci connus pour un génome particulier est appelée carte génétique.
Que sont les gènes RefSeq ?
RefSeq . La base de données des séquences de référence ( RefSeq ) est une collection en accès libre, annotée et conservée de séquences nucléotidiques (ADN, ARN) accessibles au public et de leurs produits protéiques.
Comment puis-je accéder à GenBank ?
Sélectionnez la base de données Nucleotide Collection (nr/nt) et choisissez le programme blastn, puis cliquez sur le bouton de recherche à droite. Cela permettra d’effectuer un BLAST sur l’ensemble de la base de données GenBank (à l’exclusion des EST, STS, GSS, WGS et TSA). Des bases de données NCBI plus spécifiques sont disponibles sous le sélecteur de base de données.
Que signifie la notation CDS dans une entrée GenBank ?
La traduction des acides aminés correspondant à la séquence codante nucléotidique ( CDS ). Dans de nombreux cas, les traductions sont conceptuelles. Notez que les auteurs peuvent indiquer si le CDS est basé sur des preuves expérimentales ou non expérimentales.
Qui est le père de la bioinformatique ?
Margaret Oakley Dayhoff
Utiliser un éditeur de texte (par exemple, WordPad) pour préparer le fichier FASTA des séquences de nucléotides. S'assurer d'enregistrer votre fichier en tant que Plain Text ou document texte. Si vous n'êtes pas sûr que l'option "Enregistrer" de votre programme le fasse automatiquement, utilisez "Enregistrer sous". " } }, {"@type": "Question","name": " Qu'est-ce que la base de données NCBI ? ","acceptedAnswer": {"@type": "Answer","text": " Centre national d'information sur la biotechnologie. Le NCBI abrite une série de bases de données pertinentes pour la biotechnologie et la biomédecine et constitue une ressource importante pour les outils et services bioinformatiques. Les principales bases de données comprennent GenBank pour les séquences d'ADN et PubMed, une base de données bibliographique pour la littérature biomédicale.
" } }, {"@type": "Question","name": " La GenBank est-elle une base de données primaire ? ","acceptedAnswer": {"@type": "Answer","text": " Il existe trois dépôts de nucléotides ou bases de données primaires pour la soumission des séquences de nucléotides et de génomes : GenBank" } }, {"@type": "Question","name": " Comment GenBank est-elle financée ? ","acceptedAnswer": {"@type": "Answer","text": " Le financement a été fourni par les Instituts nationaux de la santé, la Fondation nationale des sciences, le Département de l'énergie et le Département de la défense. Le LANL a collaboré à GenBank avec la firme Bolt, Beranek, et Newman, et à la fin de 1983, plus de 2 000 séquences y étaient stockées." } }, {"@type": "Question","name": " À quoi sert UniProt ? ","acceptedAnswer": {"@type": "Answer","text": " UniProt est une base de données librement accessible de séquences de protéines et d'informations fonctionnelles, de nombreuses entrées étant issues de projets de séquençage du génome. Elle contient une grande quantité d'informations sur la fonction biologique des protéines dérivées de la littérature de recherche." } }, {"@type": "Question","name": " Qu'est-ce que GenPept ? ","acceptedAnswer": {"@type": "Answer","text": " Description. La base de données GenPept est une collection de séquences basées sur des traductions de régions codantes annotées dans la GenBank." } }, {"@type": "Question","name": " Qu'est-ce que le nom du locus ? ","acceptedAnswer": {"@type": "Answer","text": " En génétique, un locus (pluriel loci) est une position spécifique et fixe sur un chromosome où se trouve un gène ou un marqueur génétique particulier. La liste ordonnée des loci connus pour un génome particulier est appelée carte génétique." } }, {"@type": "Question","name": " Que sont les gènes RefSeq ? ","acceptedAnswer": {"@type": "Answer","text": " RefSeq. La base de données des séquences de référence (RefSeq) est une collection en accès libre, annotée et conservée de séquences nucléotidiques (ADN, ARN) accessibles au public et de leurs produits protéiques." } }, {"@type": "Question","name": " Comment puis-je accéder à GenBank ? ","acceptedAnswer": {"@type": "Answer","text": " Sélectionnez la base de données Nucleotide Collection (nr/nt) et choisissez le programme blastn, puis cliquez sur le bouton de recherche à droite. Cela permettra d'effectuer un BLAST sur l'ensemble de la base de données GenBank (à l'exclusion des EST, STS, GSS, WGS et TSA). Des bases de données NCBI plus spécifiques sont disponibles sous le sélecteur de base de données." } }, {"@type": "Question","name": " Que signifie la notation CDS dans une entrée GenBank ? ","acceptedAnswer": {"@type": "Answer","text": " La traduction des acides aminés correspondant à la séquence codante nucléotidique (CDS). Dans de nombreux cas, les traductions sont conceptuelles. Notez que les auteurs peuvent indiquer si le CDS est basé sur des preuves expérimentales ou non expérimentales." } }] }