Comment construire un détecteur de plagiat en utilisant Python

Avec la popularité croissante des contenus numériques, il est devenu plus important que jamais de les protéger contre la copie et l’utilisation abusive. Un outil de détection du plagiat peut aider les enseignants à évaluer le travail des étudiants, les institutions à vérifier les documents de recherche et les écrivains à détecter le vol de leur propriété intellectuelle.
La création d’un outil de détection du plagiat peut vous aider à comprendre la correspondance des séquences, les opérations sur les fichiers et les interfaces utilisateur. Vous explorerez également les techniques de traitement du langage naturel (NLP) pour améliorer votre application.
Le module Tkinter et Difflib
Pour créer un détecteur de plagiat, vous utiliserez Tkinter et le module Difflib. Tkinter est une bibliothèque simple et multiplateforme que vous pouvez utiliser pour créer rapidement des interfaces graphiques.
Le module Difflib fait partie de la bibliothèque standard Python qui fournit des classes et des fonctions permettant de comparer des séquences telles que des chaînes de caractères, des listes et des fichiers. Il permet de créer des programmes tels qu’un correcteur automatique de texte, un système de contrôle de version simplifié ou un outil de résumé de texte.
Comment construire un détecteur de plagiat en Python
Vous pouvez trouver le code source complet pour construire un détecteur de plagiat en utilisant Python dans ce dépôt GitHub.
Importez les modules nécessaires. Définissez une méthode, load_file_or_display_contents() qui prend entrée et widget_texte comme arguments. Cette méthode charge un fichier texte et affiche son contenu dans un widget texte.
Utiliser la méthode get() pour extraire le chemin d’accès au fichier. Si l’utilisateur n’a rien saisi, utilisez la méthode askopenfilename() pour ouvrir une fenêtre de dialogue sur les fichiers afin de sélectionner le fichier souhaité pour le contrôle du plagiat. Si l’utilisateur sélectionne le chemin d’accès au fichier, effacez l’entrée précédente, le cas échéant, du début à la fin et insérez le chemin d’accès qu’il a sélectionné.
Ouvrez le fichier en mode lecture et stockez le contenu dans le fichier texte . Effacez le contenu de la variable text_widget et insérez le texte que vous avez extrait précédemment.
Définissez une méthode, compare_texte() que vous utiliserez pour comparer deux morceaux de texte et calculer leur pourcentage de similarité. Utilisez la méthode SequenceMatcher() de Difflib pour comparer des séquences et déterminer leur similarité. Définissez la fonction de comparaison personnalisée à Aucune pour utiliser la comparaison par défaut, et transmettez le texte que vous souhaitez comparer.
Utilisez la méthode ratio pour obtenir la similarité dans un format à virgule flottante que vous pouvez utiliser pour calculer le pourcentage de similarité. Utilisez la méthode get_opcodes() pour récupérer un ensemble d’opérations que vous pouvez utiliser pour mettre en évidence des portions de texte similaires et les renvoyer avec le pourcentage de similarité.
Définir une méthode, show_similarity(). Utilisez la méthode get() pour extraire le texte des deux zones de texte et le transmettre à la méthode compare_text() Effacez le contenu de la zone de texte qui affichera le résultat et insérez le pourcentage de similitude. Supprimez la fonction « même » de la mise en évidence précédente (le cas échéant).
La balise get_opcode() renvoie cinq tuples : la chaîne opcode, l’indice de début de la première séquence, l’indice de fin de la première séquence, l’indice de début de la deuxième séquence et l’indice de fin de la deuxième séquence.
La chaîne opcode peut prendre l’une des quatre valeurs suivantes : replace, delete, insert et equal. Vous obtiendrez remplacer lorsqu’une partie du texte des deux séquences est différente et que quelqu’un a remplacé une partie par une autre. Vous obtiendrez supprimer lorsqu’une partie du texte existe dans la première séquence mais pas dans la seconde.
Vous obtenez insérer lorsqu’une partie du texte est absente dans la première séquence mais présente dans la seconde. Vous obtenez égal lorsque les portions de texte sont identiques. Stockez toutes ces valeurs dans des variables appropriées. Si la chaîne d’opcode est égal ajouter la valeur même à la séquence de texte.
Initialise la fenêtre racine de Tkinter. Définir le titre de la fenêtre et définir un cadre à l’intérieur de celle-ci. Organisez le cadre avec un rembourrage approprié dans les deux directions. Définissez deux étiquettes à afficher Texte 1 et Texte 2. Définit l’élément parent dans lequel il doit résider et le texte qu’il doit afficher.
Définissez trois zones de texte, deux pour les textes que vous souhaitez comparer et une pour afficher le résultat. Déclarez l’élément parent, la largeur et la hauteur, et définissez l’option wrap à tk.WORD pour que le programme entoure les mots à la limite la plus proche et n’interrompe aucun mot entre les deux.
Définissez trois boutons, deux pour charger les fichiers et un pour les comparer. Définissez l’élément parent, le texte qu’il doit afficher et la fonction qu’il doit exécuter lorsqu’il est cliqué. Créez deux widgets d’entrée pour saisir le chemin d’accès au fichier et définissez l’élément parent ainsi que sa largeur.
Organisez tous ces éléments en lignes et en colonnes à l’aide du gestionnaire de grille. Utilisez le pack pour organiser les éléments bouton_comparaison et le bouton boîte_texte_diff. Ajoutez un rembourrage approprié si nécessaire.
Mettez en évidence le texte marqué comme identique avec un fond jaune et une couleur de police rouge.
Les mainloop() indique à Python de lancer la boucle d’événements Tkinter et d’écouter les événements jusqu’à ce que vous fermiez la fenêtre.
Assemblez le tout et exécutez le code pour détecter le plagiat.
Exemple de sortie du détecteur de plagiat
Lorsque vous exécutez le programme, une fenêtre s’affiche. En appuyant sur la touche Charger le fichier 1 une boîte de dialogue s’ouvre et vous demande de choisir un fichier. Lorsque vous choisissez un fichier, le programme affiche le contenu de la première zone de texte. En entrant le chemin d’accès et en appuyant sur Charger le fichier 2 le programme affiche le contenu de la deuxième boîte de texte. En appuyant sur la touche Comparer vous obtenez une similitude de 100 % et le texte entier est mis en surbrillance pour une similitude de 100 %.

Si vous ajoutez une autre ligne à l’une des zones de texte et que vous appuyez sur le bouton Comparez le programme met en évidence la partie similaire et laisse de côté le reste.
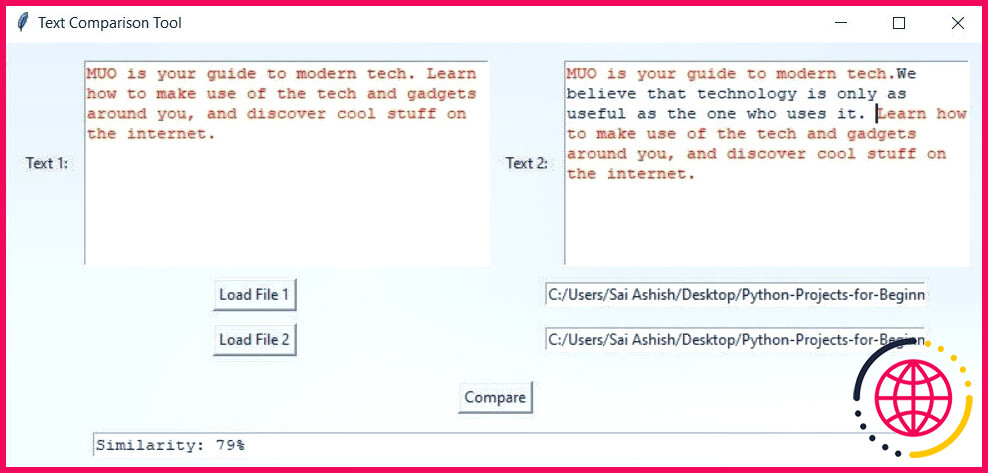
S’il y a peu ou pas de similitude, le programme met en évidence certaines lettres ou certains mots, mais le pourcentage de similitude est assez faible.

Utilisation du NLP pour la détection du plagiat
Bien que Difflib soit une méthode puissante de comparaison de textes, elle est sensible aux changements mineurs, a une compréhension limitée du contexte et est souvent inefficace pour les textes volumineux. Vous devriez envisager d’explorer le traitement du langage naturel, qui permet d’effectuer une analyse sémantique du texte, d’extraire des caractéristiques significatives et de comprendre le contexte.
En outre, vous pouvez entraîner votre modèle pour différentes langues et l’optimiser pour qu’il soit plus efficace. Parmi les techniques que vous pouvez utiliser pour la détection du plagiat, citons la similarité de Jaccard, la similarité de cosinus, l’intégration de mots, l’analyse de séquences latentes et les modèles de séquence à séquence.