Comment entraîner YOLOv8 sur des données personnalisées

YOLOv8 est un algorithme de détection d’objets en temps réel largement utilisé dans le domaine de la détection d’objets. Il fait partie de la série You Only Look Once (YOLO) développée par Ultralytics. L’algorithme suit, détecte, segmente les instances, estime la pose et classifie les objets dans les images et les vidéos. Il vise à être plus rapide et plus précis que les algorithmes précédents.
L’utilisation de YOLOv8 sur des ensembles de données expérimentales comme CIFAR-10 et CIFAR-100 est souvent plus facile pour les projets de démonstration de concept (POC) que pour les ensembles de données du monde réel qui nécessitent des ensembles de données personnalisés.
Ce tutoriel vous guidera à travers les étapes de la formation de YOLOv8 sur des données personnalisées.
Configuration de l’environnement Python
Commencez par installer l’environnement de développement pour le projet, en suivant les instructions ci-dessous.
- Allez dans le terminal et créez un nouveau répertoire nommé yolov8project:
- Naviguez vers le répertoire du projet et créez un environnement virtuel :
- Activez ensuite l’environnement virtuel. Pour exécuter votre code, vous devez installer Ultralytics, une bibliothèque de détection d’objets et de segmentation d’images. Il s’agit également d’une dépendance de YOLOv8. Installez-la à l’aide de pip en exécutant la commande ci-dessous.
- Cette commande installe le modèle pré-entraîné de YOLOv8, yolov8n.pt. Testez le modèle en exécutant les commandes ci-dessous pour effectuer une détection avec des poids pré-entraînés sur l’image ou la vidéo de votre choix, respectivement en utilisant YOLOv8. Si tout fonctionne parfaitement, les résultats seront disponibles dans le fichier yolov8project dans le répertoire runs/detect/exp dans le sous-répertoire
Préparation de votre jeu de données personnalisé
Les étapes de préparation de votre jeu de données personnalisé comprennent la collecte des données, l’étiquetage des données et le fractionnement des données (formation, test, validation).
Collecte des données
Il s’agit du processus de collecte d’un ensemble d’images comportant les objets que vous souhaitez détecter. Veillez à utiliser des images de haute qualité, mises au point et sur lesquelles les objets sont clairement visibles. Vous pouvez utiliser divers outils pour collecter des images, tels que Google Images, Flickr ou votre propre appareil photo. Si vous ne disposez pas d’un ensemble de données d’images, utilisez l’ensemble de données de la page openimages de la base de données openimages . Cet article utilise l’image de sécurité des chantiers de construction de Kaggle.
Étiquetage des données
Après avoir collecté vos images, vous devez les étiqueter. Il s’agit d’identifier les objets dans chaque image et leurs boîtes de délimitation. Plusieurs outils sont disponibles pour vous aider à étiqueter vos données, tels que LabelImg, CVAT et Roboflow. Ces outils sont tous gratuits.
Diviser les données
Pour former des modèles d’apprentissage automatique, vous devez diviser vos données en ensembles de formation et de test. Essayez d’utiliser un ratio de division de 70 à 30 % lorsque vous utilisez de grandes quantités de données. Dans le cas contraire, contentez-vous d’un ratio de 80 % à 20 % afin d’éviter que votre modèle ne soit surajouté ou sous-ajusté.
Utilisation dossiers fractionnés pour diviser aléatoirement vos données dans les ensembles de formation, de test et de validation avec le ratio de division souhaité.
Configuration de YOLOv8 pour votre jeu de données
Après avoir étiqueté vos données, configurez YOLOv8 pour votre ensemble de données personnalisé. Cela implique la création d’un fichier de configuration qui spécifie les éléments suivants :
- Le chemin d’accès à vos données d’entraînement.
- Le chemin d’accès à vos données de validation.
- Le nombre de classes que vous souhaitez détecter.
Créez un fichier config.yaml pour stocker la configuration :
La création du fichier de configuration est un moyen utile de structurer et de stocker les paramètres cruciaux pour votre modèle de vision par ordinateur. Veillez à mettre à jour le fichier config.yaml en fonction de la nature et de la structure de votre jeu de données.
Veillez à utiliser les chemins d’accès corrects pour vos ensembles de données car l’entraînement du modèle repose entièrement sur le fichier de configuration.
Entraînement de YOLOv8 sur des données personnalisées
Une fois que vous avez créé le fichier de configuration, commencez à entraîner YOLOv8. Utilisez l’outil de ligne de commande YOLOv8 pour entraîner votre modèle. L’outil de ligne de commande prend plusieurs paramètres, tels que le chemin d’accès au fichier de configuration, le nombre d’époques et la taille de l’image comme suit :
Cette commande comporte plusieurs parties.
tâche définit le type de tâche : détecter, segmenter ou classer. mode représente une action : train, predict, val, export, track ou benchmark. modèle est le modèle à utiliser, dans ce cas, yolov8n.pt. Vous pouvez également utiliser yolov8s/yolov8l/yolov8x.
époques représente le nombre de cycles de formation (10). imgsz représente la taille de l’image (640). La taille de l’image doit toujours être un multiple de 32.
Voici un exemple du résultat auquel vous pouvez vous attendre :
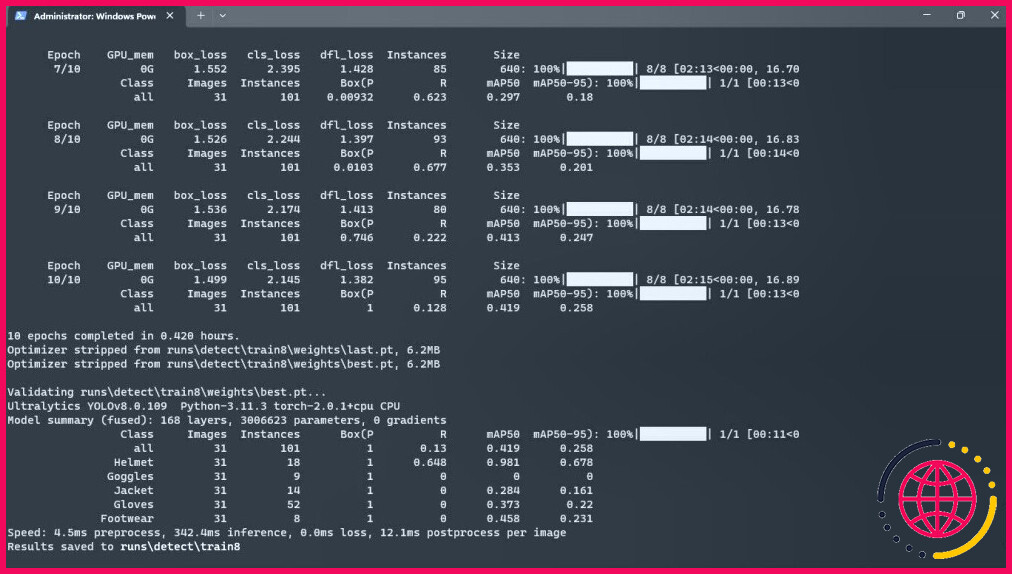
Le temps nécessaire à l’apprentissage dépend de la taille de votre ensemble de données, du nombre d’époques et du nombre de classes que vous souhaitez détecter. Une fois le processus d’entraînement terminé, vous disposerez d’un modèle YOLOv8 entraîné que vous utiliserez pour détecter des objets dans des images et des vidéos.
Une fois l’entraînement terminé, effectuez l’inférence avec les nouveaux poids, best.pt
Naviguez jusqu’à l’écran runs/train/exp/weights/best.pt pour accéder aux poids formés sur mesure. YOLOv8 aura stocké l’image prédite dans le répertoire runs/detect/exp sous-répertoire.
Évaluation des performances du modèle
Vous pouvez évaluer les performances du modèle YOLOv8 à l’aide de la commande suivante qui évalue le modèle sur un ensemble d’images de test :
Les résultats attendus sont les suivants :
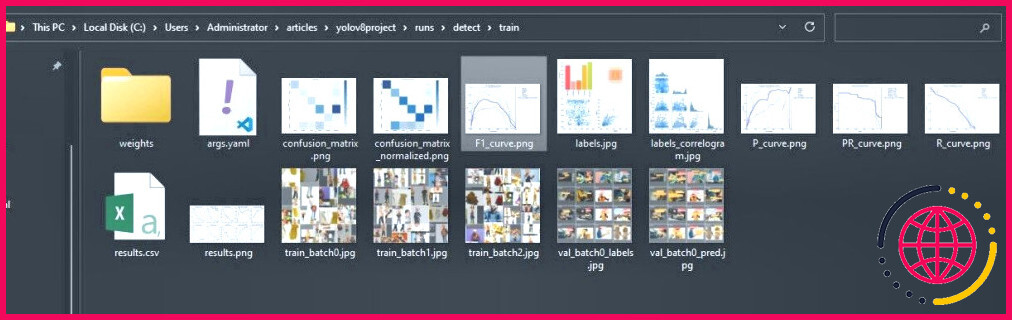
Le processus d’évaluation génère diverses mesures, telles que la précision, le rappel et le score F1. La précision mesure le pourcentage d’objets correctement détectés. Le rappel mesure le pourcentage d’objets détectés par YOLOv8. Le score F1 est une moyenne pondérée des mesures de précision et de rappel.
Déploiement de votre modèle YOLOv8 personnalisé
Testez les performances de votre modèle YOLOv8.
Le résultat est le suivant :

Ensuite, enregistrez les poids du modèle dans un fichier.
Utilisez le fichier pour charger le modèle dans votre application et l’utiliser pour détecter des objets en temps réel. Si vous déployez le modèle dans un service en nuage, utilisez le service en nuage pour détecter des objets dans les images et les vidéos qui se trouvent sur le service.
YOLOv8 à emporter
L’équipe d’Ultralytics a constamment amélioré les modèles de la série YOLO. Cela leur a permis de devenir des leaders de l’industrie en matière de technologie de détection d’objets et dans le domaine de la vision par ordinateur.
Le YOLOv8 est un modèle amélioré que vous pouvez utiliser pour gérer de nombreux types de projets de vision par ordinateur.
Comment entraîner YOLOv8 sur un jeu de données personnalisé ?
Pour entraîner YOLOv8 sur un jeu de données personnalisé, nous devons installer le paquet ultralytics. Celui-ci fournit l’interface de ligne de commande (CLI) de YOLO. Un grand avantage est que nous n’avons pas besoin de cloner le dépôt séparément et d’installer les exigences.
Comment entraîner YOLOv5 avec vos propres données ?
Entraînement avec des données personnalisées
- Créer un jeu de données. Les modèles YOLOv5 doivent être entraînés sur des données étiquetées afin d’apprendre les classes d’objets dans ces données.
- 1.1 Collecte d’images. Votre modèle apprendra par l’exemple.
- 1.2 Créer des étiquettes.
- 1.3 Préparer le jeu de données pour YOLOv5.
- 1.1 Créer dataset.yaml.
- 1.2 Créer les étiquettes.
- 1.3 Organiser les répertoires.
- Sélectionner un modèle.
Comment entraîner un darknet sur un jeu de données personnalisé ?
Entraînement d’un darknet sur un jeu de données personnalisé
- Étape 1 : Obtenez le Darknet Repo localement et configurez les dossiers de données.
- Étape 2 : Créez le Darknet.
- Étape 3 : Configurez le dossier darknet/data.
- Étape 4 : Installation du dossier cfg.
- Étape 5 : Téléchargez les fichiers de poids.
- Étape 6 : Modifier les fichiers de configuration pour l’amélioration de mAP.
- Étape 6 : Exécutez Darknet.
Comment affiner un modèle YOLOv8 ?
Le processus de mise au point d’un modèle YOLOv8 peut être décomposé en trois étapes : la création et l’étiquetage du jeu de données, l’entraînement du modèle et son déploiement. Dans ce tutoriel, nous allons couvrir les deux premières étapes en détail, et montrer comment utiliser notre nouveau modèle sur n’importe quel fichier ou flux vidéo entrant.