Comment consolider plusieurs classeurs Excel avec Python

Python, en tant que langage, est une action antérieure bénéfique, en particulier lorsque vous souhaitez collaborer avec des données organisées. Étant donné que les particuliers conservent beaucoup de données dans des fichiers Excel, il est important de régler plusieurs documents pour économiser du temps et des efforts.
Python vous permet de faire exactement cela ; quel que soit le nombre de documents Excel que vous avez l’intention d’incorporer, vous pouvez le faire avec la simplicité d’un membre de la famille. Proposé sa série de collections ainsi que des ressources tierces, vous pouvez importer et également utiliser les appareils à multiples facettes de Python pour effectuer votre processus d’appel d’offres.
Dans cet aperçu, vous devrez certainement monter et utiliser les bibliothèques Pandas pour importer des informations directement dans Python avant de les combiner.
Installer les bibliothèques Pandas en Python
Pandas est une collection tierce que vous pouvez monter en Python. Certains IDE contiennent actuellement des Pandas.
Si vous utilisez une variante IDE qui n’inclut pas les Pandas préinstallés, soyez confiant, vous pouvez l’installer directement en Python.
Voici comment configurer Pandas :
Si vous utilisez Jupyter Notebook, vous pouvez configurer Pandas directement avec la commande PIP. Principalement, lorsque vous avez installé Jupyter avec Anaconda, il existe de grandes possibilités d’avoir déjà des Pandas proposés pour une utilisation directe.
Si vous ne pouvez pas appeler Pandas, vous pouvez utiliser la commande ci-dessus pour les monter directement.
Combiner des fichiers Excel avec Python
Tout d’abord, vous devez créer un dossier à l’emplacement de votre choix avec tous les documents Excel. Une fois le dossier prêt, vous pouvez commencer à composer le code pour importer les bibliothèques.
Vous utiliserez deux variables dans ce code :
- Panda : La bibliothèque Pandas fournit les cadres de données pour stocker les fichiers Excel.
- SE : La bibliothèque est utile pour vérifier les données du dossier de votre équipement
Pour importer ces collections, utilisez ces commandes :
- Importer: Structure de phrase Python utilisée pour importer les bibliothèques en Python
- Panda : Nom de la bibliothèque
- pd : Alias fourni à la bibliothèque
- SE : Une bibliothèque pour accéder au dossier système
Une fois que vous avez importé les collections, créez 2 variables pour stocker les données d’entrée et de résultat. Le cours de documents d’entrée est nécessaire pour accéder au dossier des fichiers. Le cours sur les documents de résultat est nécessaire car le fichier combiné y sera exporté.
Si vous utilisez Python, veillez à transformer la barre oblique inverse en barre oblique ( pour / )
Joindre le / à la fin aussi pour compléter les chemins.
Les fichiers du dossier sont disponibles dans une liste de contrôle. Créez une liste de contrôle pour stocker toutes les références de données du dossier d’entrée à l’aide de la répertoire_liste fonction de la SE bibliothèque.
Si vous n’êtes pas sûr des fonctionnalités disponibles dans une bibliothèque, vous pouvez utiliser le directeur fonction avec le nom de la collection. Par exemple, pour vérifier la variation exacte de la fonctionnalité listdir, vous pouvez utiliser la commande comme suit :
La sortie comprendra certainement toutes les fonctionnalités connectées disponibles dans la bibliothèque du système d’exploitation. La fonction listdir fait partie des nombreuses fonctions facilement disponibles dans cette bibliothèque.
Créez une nouvelle variable pour enregistrer les documents d’entrée du dossier.
Imprimez cette variable pour voir les noms des fichiers stockés dans le dossier. Toutes les données stockées dans le dossier sont affichées une fois que vous utilisez la fonction d’impression.
Ensuite, vous devez ajouter un nouveau cadre d’information pour stocker chaque donnée Excel. Imaginez une structure de données comme un conteneur pour enregistrer des données. Voici la commande pour produire un cadre d’information.
- df : Variable pour conserver la valeur du DataFrame
- pd : Alias pour la bibliothèque Pandas
- Trame de données: Syntaxe par défaut pour inclure une structure de données
Le dossier d’entrée a 3 . xlsx données dans cet exemple. Les noms des documents sont :
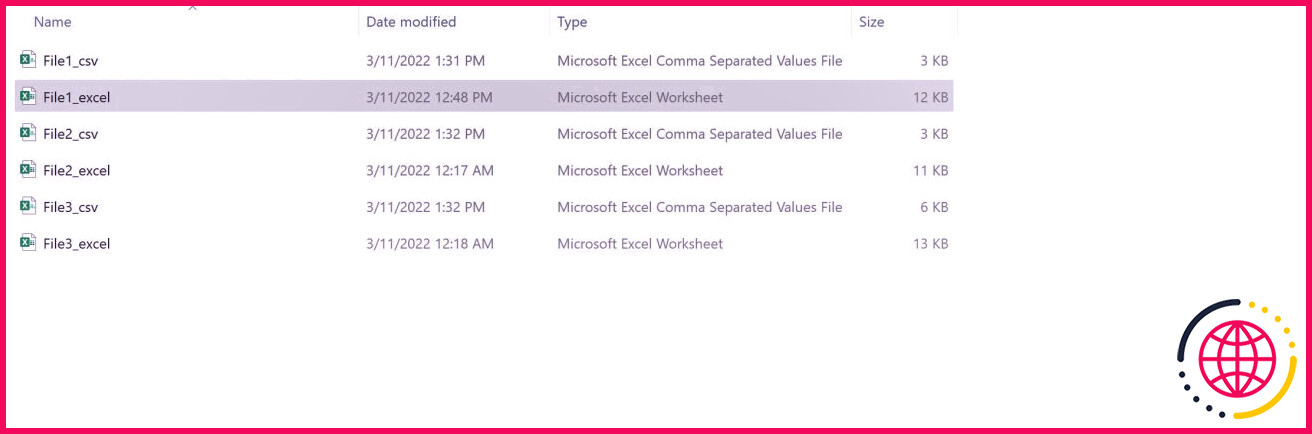
Pour ouvrir chaque donnée de ce dossier, vous devez exécuter une échappatoire. La faille fonctionnera pour chacun des documents de la liste développée au-dessus.
Voici exactement comment vous pouvez le faire :
Ensuite, il est nécessaire d’examiner les extensions des documents étant donné que le code n’ouvrira certainement que les données XLSX. Pour vérifier ces fichiers, vous pouvez utiliser un Si déclaration.
Utilisez le se termine par fonction pour cette fonction, conformément à :
- excel_documents : Liste avec toutes les valeurs du fichier
- se termine par: Fonction d’examen de l’expansion des documents
- (« ».xlsx ») : Cette valeur de chaîne peut se transformer, selon ce que vous souhaitez rechercher
Maintenant que vous avez déterminé les documents Excel, vous pouvez produire une nouvelle structure de données pour réviser et conserver les documents individuellement.
- df 1 : Nouvelle trame d’information
- pd : Collection Pandas
- lire _ se démarquer : Fonction pour lire les fichiers Excel dans la collection Pandas
- entrée _ chemin_fichier : Chemin du dossier où sont conservées les données
- excel_fichiers : Toute variable utilisée dans la boucle for
Pour commencer à ajouter les données, vous devez utiliser le ajouter une fonction.
Enfin, puisque le bloc de données combiné se prépare, vous pouvez l’exporter vers l’emplacement du résultat. Dans ce cas, vous exportez la structure d’information vers une donnée XLSX.
- df : Dataframe à exporter
- de se démarquer: Commande utilisée pour exporter les données
- sortie _ chemin_fichier : Chemin spécifié pour conserver la sortie
- Fichier _ consolidé.xlsx : Nom des documents consolidés
Voyons maintenant le code final :
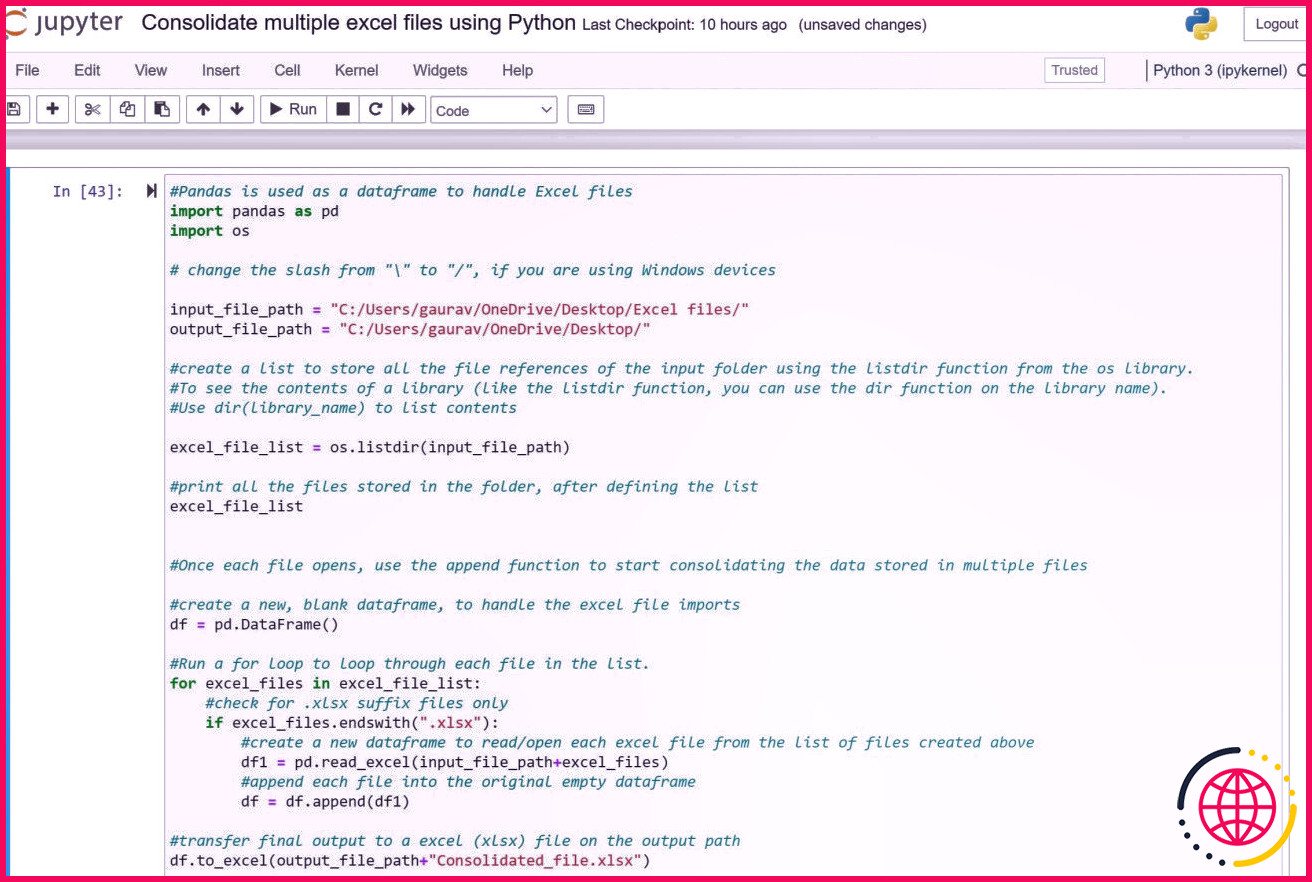
Utilisation de Python pour combiner plusieurs classeurs Excel
Python’s Pandas est un superbe appareil pour les débutants comme pour les utilisateurs avancés. La bibliothèque est utilisée à fond par les concepteurs qui souhaitent maîtriser Python.
Même si vous êtes un débutant, vous pouvez bénéficier exceptionnellement en apprenant les nuances de Pandas et aussi exactement comment la collection est utilisée dans Python.