Pandas contre Polars : La bataille de la performance

En effectuant des tâches d’analyse de données, il y a de fortes chances que vous ayez rencontré Pandas. Il s’agit de la bibliothèque la plus répandue dans le domaine de l’analyse de données depuis longtemps. Polars, en revanche, est une bibliothèque relativement récente qui se targue de performances élevées et d’une grande efficacité en termes de mémoire. Mais laquelle est la meilleure ?
Ici, vous verrez une comparaison des performances entre Pandas et Polars à travers une gamme de tâches courantes de manipulation de données.
Mesurer les performances : Métriques et ensemble de données de référence
Cette comparaison tient compte de la capacité de Pandas et de Polars à effectuer des tâches courantes de manipulation de données. Polars à manipuler l’ensemble de données Black Friday Sale de Kaggle. Cet ensemble de données contient 550 068 lignes de données. Il comprend des informations sur les données démographiques des clients, l’historique des achats et les détails des produits.
Pour garantir des mesures de performance équitables, la comparaison utilisera le temps d’exécution comme mesure de performance standard pour chaque tâche. La plateforme utilisée pour exécuter le code de chaque tâche de comparaison sera Google Colab.
Le code source complet qui compare les bibliothèques Pandas et Polars est disponible dans un dépôt GitHub.
Lecture de données à partir d’un fichier CSV
Cette tâche compare le temps nécessaire à chaque bibliothèque pour lire les données de l’ensemble de données Black Friday Sale. Le jeu de données est au format CSV. Pandas et Polars offrent des fonctionnalités similaires pour cette tâche.
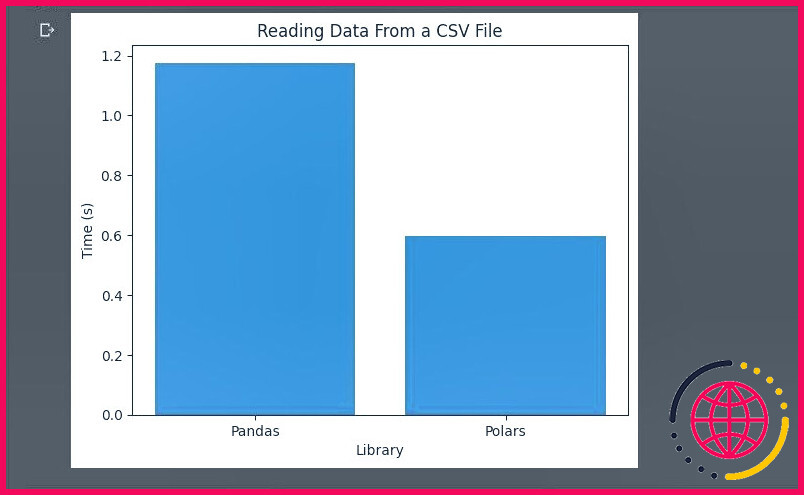
Pandas prend deux fois plus de temps que Polars pour lire les données du jeu de données Black Friday Sale.
Sélection des colonnes
Cette tâche mesure le temps nécessaire à chaque bibliothèque pour sélectionner les colonnes de l’ensemble de données. Elle consiste à sélectionner les colonnes de l’ensemble de données. ID_utilisateur et Achat colonnes.
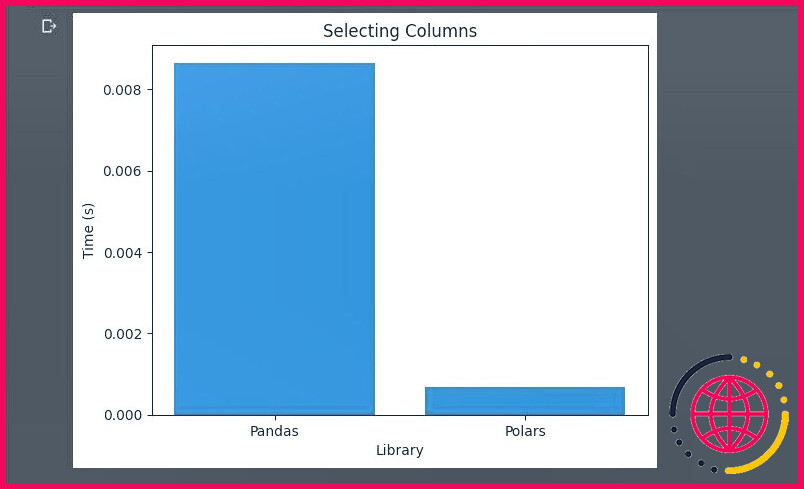
Les Polars prennent beaucoup moins de temps que les Pandas pour sélectionner des colonnes dans l’ensemble de données.
Filtrage des lignes
Cette tâche compare les performances de chaque bibliothèque en matière de filtrage des lignes lorsque le paramètre Le genre est F dans l’ensemble de données.
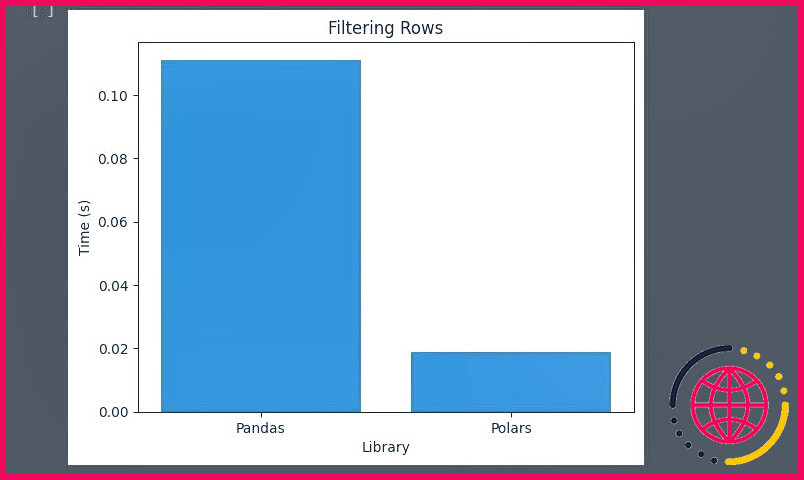
Les Polars prennent très peu de temps par rapport aux Pandas pour filtrer les lignes.
Regroupement et agrégation des données
Cette tâche consiste à regrouper les données en fonction d’une ou plusieurs colonnes. Ensuite, elle exécute certaines fonctions d’agrégation sur les groupes. Elle mesure le temps nécessaire à chaque bibliothèque pour regrouper les données par colonne. Genre et calculer le montant moyen des achats pour chaque groupe.
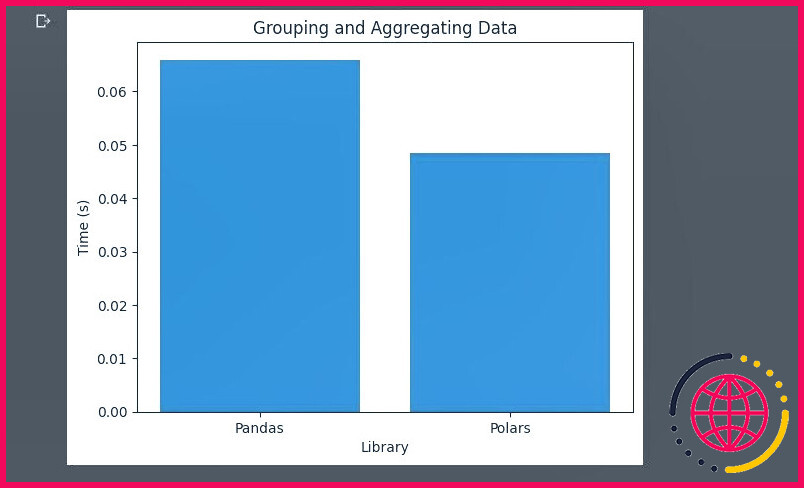
Une fois de plus, les Polars sont plus performants que les Pandas. Mais la marge n’est pas aussi importante que celle du filtrage des lignes.
Application de fonctions aux données
Cette tâche consiste à appliquer une fonction à une ou plusieurs colonnes. Elle mesure le temps qu’il faut à chaque bibliothèque pour multiplier la valeur de la fonction. Achat par 2.
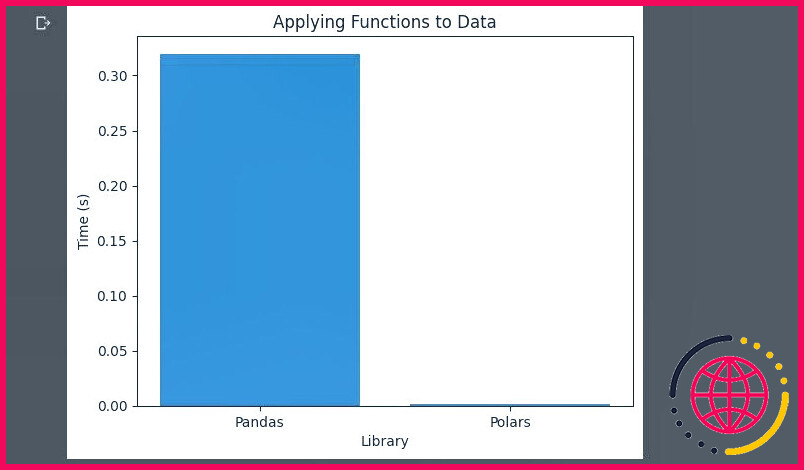
On voit à peine la barre des Polars. Les Polars surpassent une fois de plus les Pandas.
Fusion de données
Cette tâche consiste à fusionner deux ou plusieurs DataFrames sur la base de l’existence d’une ou plusieurs colonnes communes. Elle mesure le temps nécessaire à chaque bibliothèque pour fusionner les DataFrames ID_utilisateur et Achat de deux DataFrames distincts.
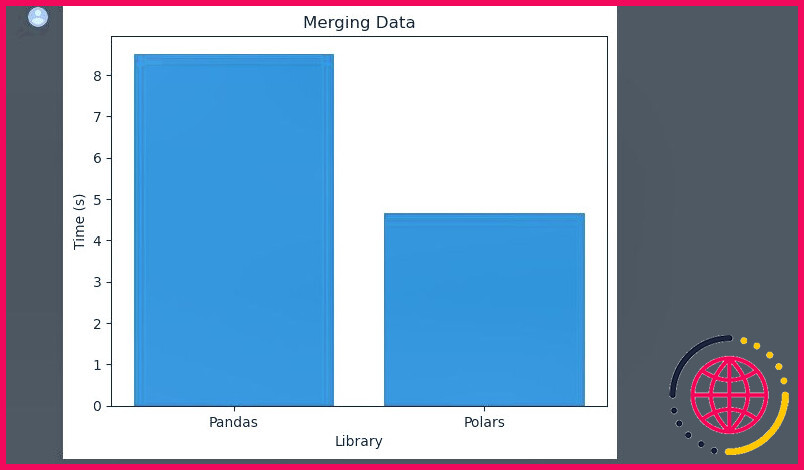
Les deux bibliothèques mettent un certain temps à accomplir cette tâche. Mais Polars prend presque la moitié du temps que prend Pandas pour fusionner les données.
Pourquoi Polars est-il plus performant que Pandas ?
Dans toutes les tâches de manipulation de données ci-dessus, Polars est plus performant que Pandas. Il y a plusieurs raisons pour lesquelles Polars peut être plus performant que Pandas en termes de temps d’exécution.
- Optimisation de la mémoire: Polars utilise Rust, un langage de programmation système qui optimise l’utilisation de la mémoire. Cela permet à Polars de minimiser le temps qu’il passe sur l’allocation et la désallocation de la mémoire. Cela rend le temps d’exécution plus rapide.
- Opérations SIMD (Single Instruction Multiple Data): Polars utilise des opérations SIMD pour effectuer des calculs sur les données. Cela signifie qu’il peut utiliser une seule instruction pour effectuer la même opération sur plusieurs éléments de données simultanément. Cela permet à Polars d’effectuer des opérations beaucoup plus rapidement que Pandas, qui utilise une approche à un seul thread.
- Évaluation paresseuse: Polars utilise l’évaluation paresseuse pour retarder l’exécution des opérations jusqu’à ce qu’il en ait besoin. Cela permet de réduire le temps que Polars consacre aux opérations inutiles et d’améliorer les performances.
Développez vos compétences en science des données
Il existe de nombreuses bibliothèques Python qui peuvent vous aider dans la science des données. Pandas et Polars n’en sont qu’une petite partie. Pour améliorer les performances de votre programme, vous devriez vous familiariser avec d’autres bibliothèques de science des données. Cela vous aidera à comparer et à choisir la bibliothèque qui convient le mieux à votre cas d’utilisation.
S’abonner à notre lettre d’information
Comment les polars sont-ils plus rapides que les pandas ?
Polars est beaucoup plus rapide que les bibliothèques qui essaient d’implémenter la concurrence en utilisant Python, comme Pandas. C’est parce que Polars est écrit avec Rust, et que Rust est bien meilleur que Python pour implémenter la concurrence.
Quelle est la différence entre Pandas et Polars ?
Polars utilise les tableaux Apache Arrow pour représenter les données en mémoire alors que Pandas utilise les tableaux Numpy. Polars représente les données en mémoire avec des tableaux Arrow tandis que Pandas représente les données en mémoire avec des tableaux Numpy.




