Comment télécharger et installer localement Llama 2

Meta a publié Llama 2 au cours de l’été 2023. La nouvelle version de Llama est affinée avec 40% de tokens en plus que le modèle Llama original, doublant la longueur de son contexte et surpassant de manière significative les autres modèles open-source disponibles. Le moyen le plus rapide et le plus simple d’accéder à Llama 2 est d’utiliser une API via une plateforme en ligne. Toutefois, si vous souhaitez bénéficier d’une expérience optimale, il est préférable d’installer et de charger Llama 2 directement sur votre ordinateur.
Dans cette optique, nous avons créé un guide étape par étape sur la façon d’utiliser Text-Generation-WebUI pour charger un LLM quantifié de Llama 2 localement sur votre ordinateur.
Pourquoi installer Llama 2 localement ?
Il y a de nombreuses raisons pour lesquelles les gens choisissent d’exécuter Llama 2 directement. Certains le font pour des raisons de confidentialité, d’autres pour la personnalisation et d’autres encore pour les capacités hors ligne. Si vous êtes en train de faire des recherches, de peaufiner ou d’intégrer Llama 2 à vos projets, l’accès à Llama 2 via l’API n’est peut-être pas ce qu’il vous faut. L’intérêt d’exécuter un LLM localement sur votre PC est de réduire la dépendance à l’égard d’outils d’IA tiers et d’utiliser l’IA à tout moment et en tout lieu, sans craindre de divulguer des données potentiellement sensibles à des entreprises et à d’autres organisations.
Ceci étant dit, commençons par le guide étape par étape de l’installation locale de Llama 2.
Étape 1 : installer l’outil de construction Visual Studio 2019
Pour simplifier les choses, nous utiliserons un programme d’installation en un clic pour Text-Generation-WebUI (le programme utilisé pour charger Llama 2 avec l’interface graphique). Cependant, pour que ce programme d’installation fonctionne, vous devez télécharger l’outil de construction Visual Studio 2019 et installer les ressources nécessaires.
Télécharger : Visual Studio 2019 (Gratuit)
- Allez-y et téléchargez l’édition communautaire du logiciel.
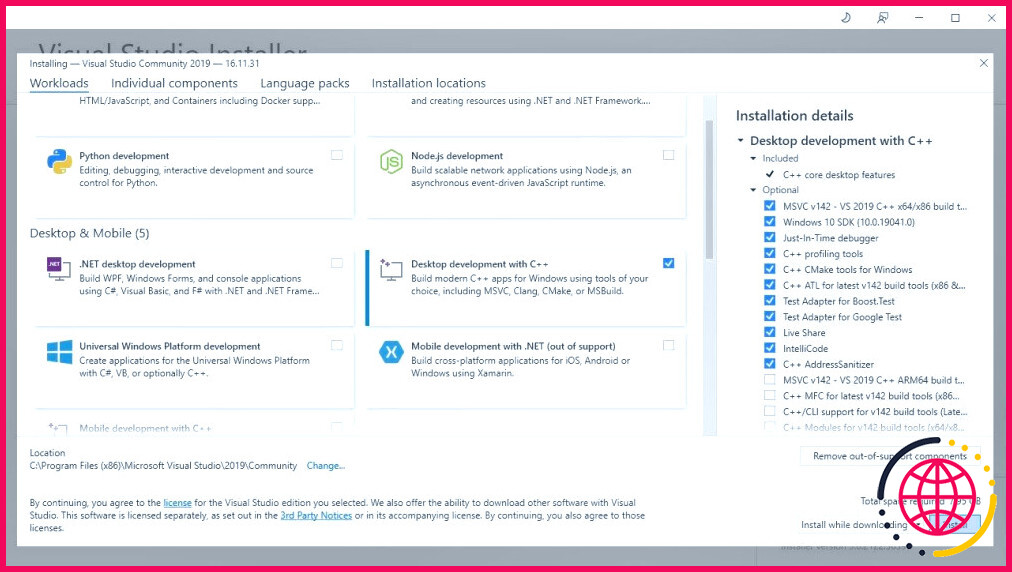
- Installez maintenant Visual Studio 2019, puis ouvrez le logiciel. Une fois ouvert, cochez la case sur Développement de bureau avec C++ et cliquez sur installer.

Maintenant que vous avez installé Desktop development with C++, il est temps de télécharger le programme d’installation en un clic de Text-Generation-WebUI.
Étape 2 : Installation de Text-Generation-WebUI
Le programme d’installation en un clic de Text-Generation-WebUI est un script qui crée automatiquement les dossiers nécessaires et met en place l’environnement Conda et toutes les conditions requises pour exécuter un modèle d’IA.
Pour installer le script, téléchargez le programme d’installation en un clic en cliquant sur Code > Télécharger le ZIP.
Télécharger : Installateur Text-Generation-WebUI (Gratuit)
- Une fois téléchargé, extrayez le fichier ZIP à l’endroit de votre choix, puis ouvrez le dossier extrait.
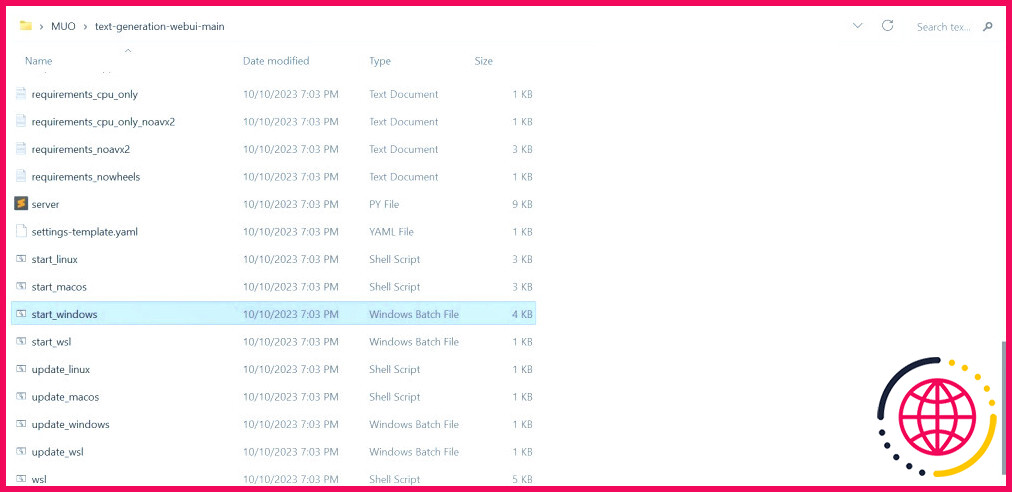
- Dans le dossier, faites défiler vers le bas et recherchez le programme de démarrage approprié pour votre système d’exploitation. Exécutez les programmes en double-cliquant sur le script approprié.
- Si vous êtes sous Windows, sélectionnez démarrer_fenêtres fichier batch
- pour MacOS, sélectionnez start_macos scripts shell
- pour Linux, start_linux script shell.

- Il se peut que votre antivirus émette une alerte, ce qui n’est pas grave. L’invite n’est qu’un faux positif de l’antivirus pour l’exécution d’un fichier batch ou d’un script. Cliquez sur Exécuter quand même.
- Un terminal s’ouvre et démarre l’installation. Au début, l’installation s’interrompt et vous demande quel GPU vous utilisez. Sélectionnez le type approprié de GPU installé sur votre ordinateur et appuyez sur Entrée. Pour ceux qui n’ont pas de carte graphique dédiée, sélectionnez Aucun (je veux exécuter les modèles en mode CPU). Gardez à l’esprit que l’exécution en mode CPU est beaucoup plus lente que l’exécution du modèle avec un GPU dédié.

- Une fois la configuration terminée, vous pouvez maintenant lancer Text-Generation-WebUI localement. Vous pouvez le faire en ouvrant votre navigateur web préféré et en entrant l’adresse IP fournie dans l’URL.

- L’interface WebUI est maintenant prête à l’emploi.

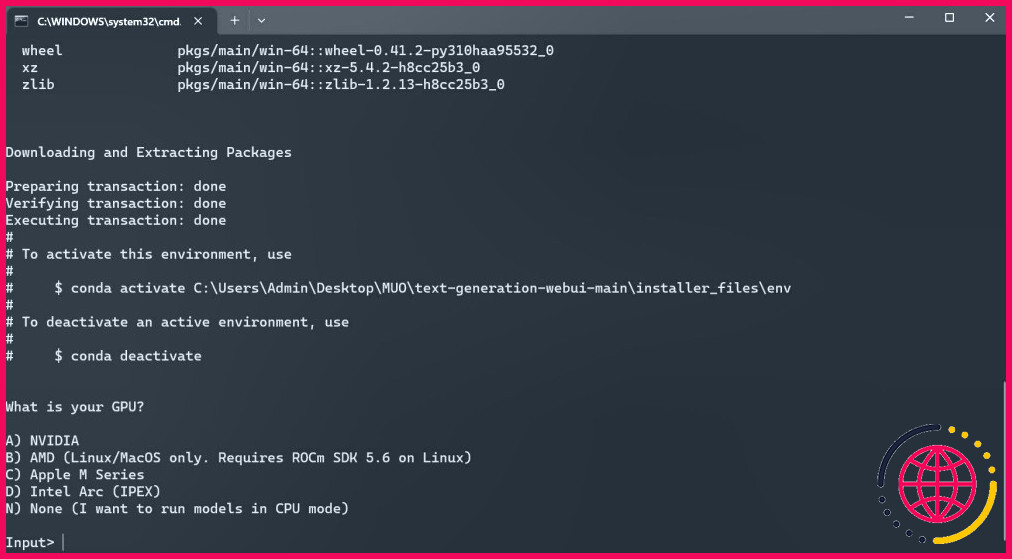

Cependant, le programme n’est qu’un chargeur de modèle. Téléchargez Llama 2 pour que le chargeur de modèles puisse être lancé.
Étape 3 : Téléchargement du modèle Llama 2
Il y a un certain nombre de choses à prendre en compte lorsque vous décidez de l’itération de Llama 2 dont vous avez besoin. Il s’agit notamment des paramètres, de la quantification, de l’optimisation matérielle, de la taille et de l’utilisation. Toutes ces informations sont indiquées dans le nom du modèle.
- Paramètres : Le nombre de paramètres utilisés pour former le modèle. Des paramètres plus importants permettent d’obtenir des modèles plus performants, mais au détriment des performances.
- Utilisation : Peut être standard ou chat. Un modèle chat est optimisé pour être utilisé comme un chatbot tel que ChatGPT, tandis que le modèle standard est le modèle par défaut.
- Optimisation du matériel : Indique le matériel le plus adapté au modèle. GPTQ signifie que le modèle est optimisé pour fonctionner sur un GPU dédié, tandis que GGML est optimisé pour fonctionner sur un CPU.
- Quantification : Indique la précision des poids et des activations dans un modèle. Pour l’inférence, une précision de q4 est optimale.
- Taille : Fait référence à la taille du modèle spécifique.
Notez que certains modèles peuvent être agencés différemment et peuvent même ne pas avoir les mêmes types d’informations affichées. Cependant, ce type de convention de nommage est assez courant dans la bibliothèque de modèles HuggingFace, il est donc utile de le comprendre.
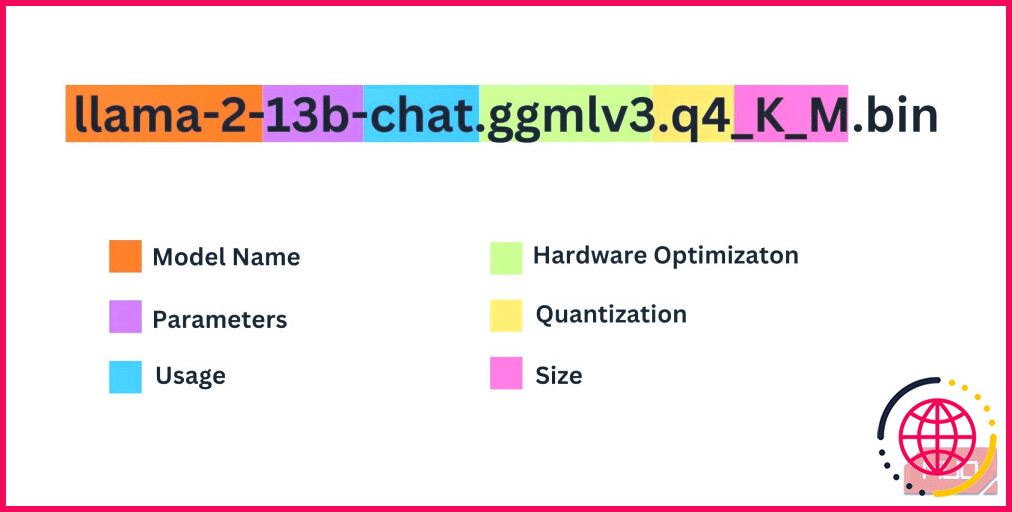
Dans cet exemple, le modèle peut être identifié comme un modèle Llama 2 de taille moyenne formé sur 13 milliards de paramètres optimisés pour l’inférence de chat à l’aide d’un processeur dédié.
Pour les modèles fonctionnant sur un GPU dédié, choisissez une valeur de GPTQ tandis que pour ceux qui utilisent un CPU, choisissez le modèle GGML. Si vous souhaitez discuter avec le modèle comme vous le feriez avec ChatGPT, choisissez chat mais si vous voulez expérimenter le modèle avec toutes ses capacités, utilisez l’option standard standard. En ce qui concerne les paramètres, sachez que l’utilisation de modèles plus grands donnera de meilleurs résultats au détriment des performances. Je vous recommande personnellement de commencer avec un modèle 7B. En ce qui concerne la quantification, utilisez q4, car elle ne sert qu’à l’inférence.
Télécharger : GGML (Gratuit)
Télécharger : GPTQ (Gratuit)
Maintenant que vous savez de quelle itération de Llama 2 vous avez besoin, allez-y et téléchargez le modèle que vous voulez.
Dans mon cas, comme je travaille sur un ultrabook, j’utiliserai un modèle GGML adapté au chat, llama-2-7b-chat-ggmlv3.q4_K_S.bin.
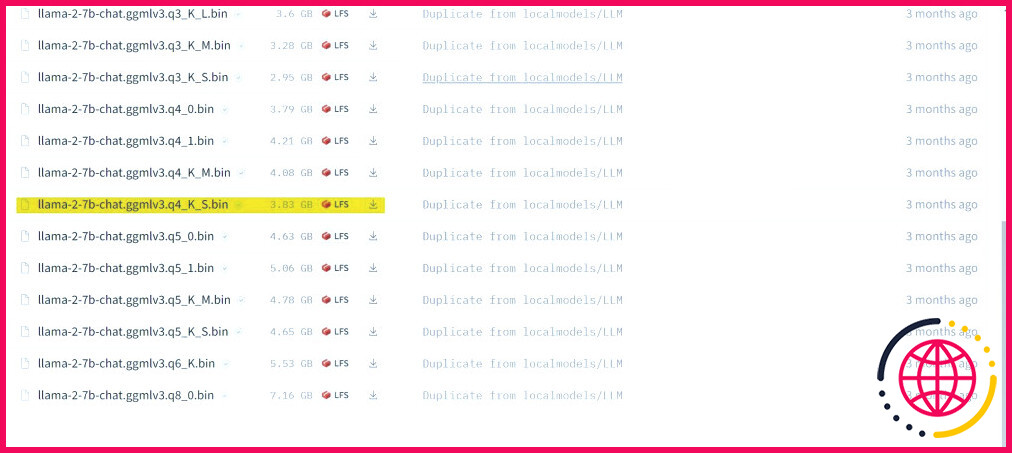
Une fois le téléchargement terminé, placez le modèle dans text-generation-webui-main > modèles.
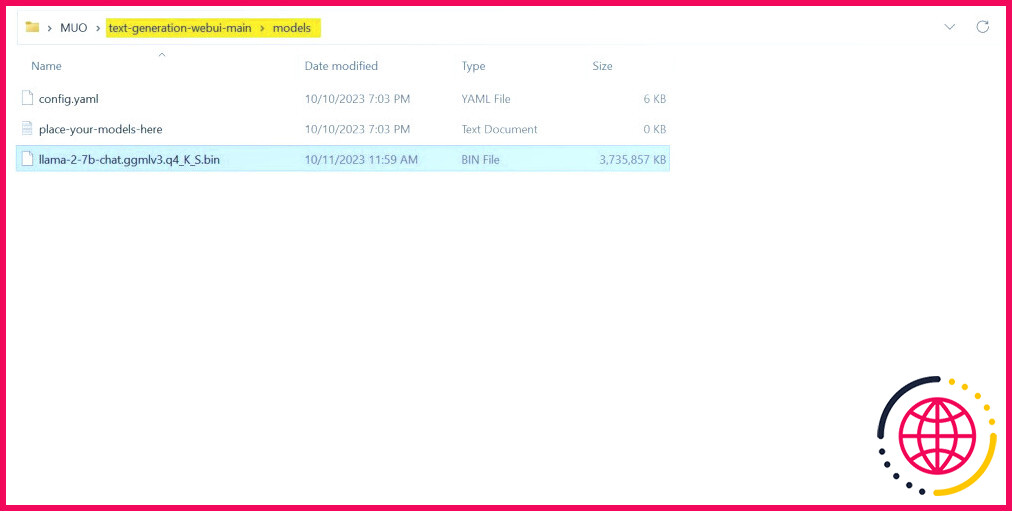
Maintenant que votre modèle est téléchargé et placé dans le dossier model, il est temps de configurer le chargeur de modèle.
Étape 4 : configuration de l’interface Web de génération de texte
Commençons maintenant la phase de configuration.
- Une fois de plus, ouvrez Text-Generation-WebUI en exécutant la commande start_(votre OS) (voir les étapes précédentes).
- Dans les onglets situés au-dessus de l’interface graphique, cliquez sur Modèle. Cliquez sur le bouton d’actualisation au niveau du menu déroulant du modèle et sélectionnez votre modèle.
- Cliquez maintenant sur le menu déroulant du modèle Chargeur de modèles et sélectionnez AutoGPTQ pour ceux qui utilisent un modèle GTPQ et ctransformateurs pour ceux qui utilisent un modèle GGML. Enfin, cliquez sur Charger pour charger votre modèle.

- Pour utiliser le modèle, ouvrez l’onglet Chat et commencez à tester le modèle.
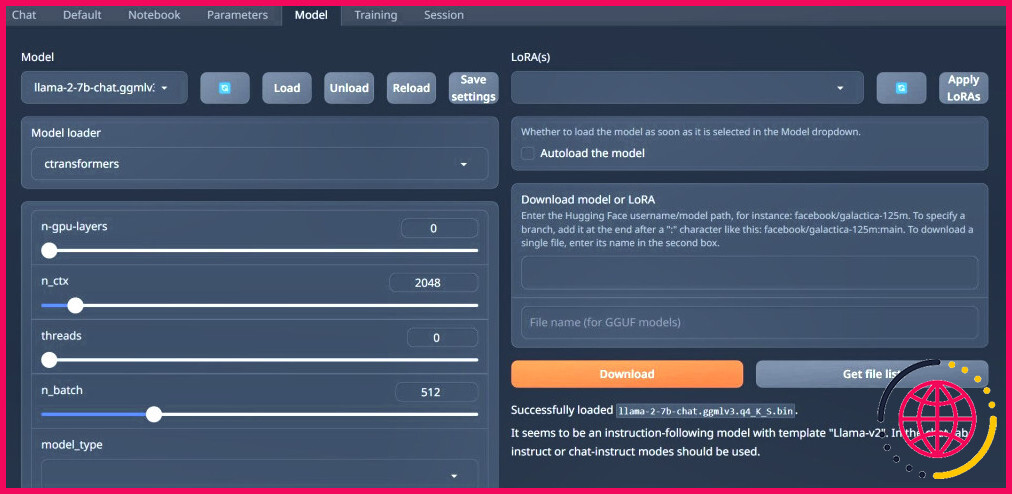

Félicitations, vous avez réussi à charger Llama2 sur votre ordinateur local !
Essayer d’autres LLM
Maintenant que vous savez comment exécuter Llama 2 directement sur votre ordinateur à l’aide de Text-Generation-WebUI, vous devriez également être en mesure d’exécuter d’autres LLM en plus de Llama. Souvenez-vous simplement des conventions de dénomination des modèles et du fait que seules les versions quantifiées des modèles (généralement de précision q4) peuvent être chargées sur des PC ordinaires. De nombreux LLM quantifiés sont disponibles sur HuggingFace. Si vous souhaitez explorer d’autres modèles, recherchez TheBloke dans la bibliothèque de modèles de HuggingFace, et vous devriez trouver de nombreux modèles disponibles.